작업확경: Colab Notebook
댓글을 봤을 때, 긍정/부정을 판단하는 인공지능을 만들려고 한다.
ㄴ 긍정/부정을 판단하는 인공지능이기에, supervised Learning!
ex) YELP 서비스의 리뷰 분석 (NLP)
ㄴ stars 컬럼은, 유저가 1점부터 5점까지 준 별점이 들어있다.
ㄴ text 컬럼은, 별점을 준 유저의 리뷰가 들어있다.
ㄴ cool, useful, funny 컬럼은, 다른사람들이 이 리뷰 글에 투표한 숫자다. 따라서 쿨이 3개이면, 이 리뷰에 대해서 3명이 쿨에 공감했다는 뜻이다.
- import libraries
| import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline |
ㄴ 구글 Colab에는 fbprophet 라이브러리가 이미 설치 되어있어서, 따로 설치가 필요없다.
- Colab에서 이용시
- 또한, 불러오고자 하는 파일이 구글드라이브 Colab Notebook 폴더에 업로드가 되어있어야한다.
| from google.colab import drive drive.mount('/content/drive') import os os.chdir('/content/drive/MyDrive/Colab Notebooks') |

- 별점 5점과 1점은 확실한 긍정/부정이므로, 애매한 2,3,4는 배제하고 학습시키도록 한다.
ex) 별점이 1점인 리뷰의 데이터 프레임과 별점이 5점인 데이터프레임을 각각 따로 변수에 저장하고, 두개의 데이터 프레임을 하나로 합치시오. 긍정과 부정의 리뷰 학습을 위해서 하나로 합칩니다.
| yelp_df_1 = yelp_df.loc[yelp_df['stars'] == 1,] yelp_df_5 =yelp_df.loc[yelp_df['stars'] == 5,] yelp_df_1_5 = pd.concat([yelp_df_1,yelp_df_5]) # 아래처럼 가져와도 된다. yelp_df.loc[(yelp_df['stars'] ==1) | (yelp_df['stars'] ==5) ,] |

ex) 구두점/ STOPWORDS(불용어) 제거하고, Count Vectorizer를 사용하여 문자를 숫자로 바꿔준다.
- 구두점/불용어 제거 함수
| import string import nltk nltk.download('stopwords') from nltk.corpus import stopwords my_stopwords = stopwords.words('english') def message_cleaning(sentence) : # 1. 구두점 제거 Test_punc_removed = [char for char in sentence if char not in string.punctuation] # 2. 각 글자들을 하나의 문자열로 합친다. Test_punc_removed_join = ''.join(Test_punc_removed) # 3. 문자열에 불용어가 포함되어잇는지 확인해서, 불용어 제거한다. Test_punc_removed_join_clean = [word for word in Test_punc_removed_join.split() if word.lower() not in my_stopwords] # 4. 결과로 남은 단어들만 리턴한다. return Test_punc_removed_join_clean |
| from sklearn.feature_extraction.text import CountVectorizer vec = CountVectorizer(analyzer = message_cleaning) # transform 하기 전에 애널라이저를 먼저 시행한다. X = vec.fit_transform(yelp_df_1_5['text']) # 바꿔달라 # fit: 텍스트에 있는 내용을 몇개가 문자가 나왔는지, 구두점 제거하고 전체 리뷰에서 몇개가 쓰였는지, 컬럼으로 만든다. # 바꿔서, 정렬해서, 일렬로 만들어가지고. # 글이 있어야한다. 그 글이 X # 이 글을 주고, 이 글이 1점받은 글인지, 5점받은 글인지 판단하게 하는 학습을 시키는 것. |

ㄴ 별점 1점과 5점 합친 데이터가, 4,086개(행), 컬럼이 26435개, 리뷰에 적는 단어가 약 2만6천단어가 쓰이고, 보통 많이 써봤자 2만 6천 단어 안팎이라는 것을 알수 있음.
| vec = CountVectorizer(analyzer = message_cleaning) X = vec.fit_transform(yelp_df_1_5['text']) |
| # 실제 넘파이 어레이로 X가 되어있어야한다. X = X.toarray() # y는 별점 = 정답지가 있어야한다. # 애매한 2,3,4점은 빼고, 확실한 1점과 5점으로만 가야해서, 1과 5점만으로만 학습 시킨다. y = yelp_df_1_5['stars'] |
- 학습용과 테스트용으로 데이터프레임을 나눈다. 테스트용은 20%로 설정한다. 그리고 나이브베이즈 모델링을 한다.
| from sklearn.model_selection import train_test_split X_train,X_test,y_train,y_test = train_test_split(X,y, test_size = 0.2,random_state=7) from sklearn.naive_bayes import MultinomialNB,GaussianNB classifier1 = MultinomialNB() classifier1.fit(X_train, y_train) classifier2 = GaussianNB() classifier2.fit(X_train, y_train) from sklearn.metrics import confusion_matrix,accuracy_score y_pred1 = classifier1.predict(X_test) y_pred2 = classifier2.predict(X_test) |
- 테스트셋으로 모델 평가. 컨퓨전 매트릭스를 사용한다.
| from sklearn.metrics import confusion_matrix,accuracy_score confusion_matrix(y_test,y_pred1) accuracy_score(y_test,y_pred1) confusion_matrix(y_test,y_pred2) accuracy_score(y_test,y_pred2) |

- 히트맵으로 성과를 표시해보자
| sns.heatmap(data = confusion_matrix(y_test,y_pred1), annot = True, cmap = 'RdPu', fmt = '.0f') # 1이 0이다. 부정 # 5가 1이다. 긍정 # 정확도가 90%면, 실무에 적용할만 하다. |
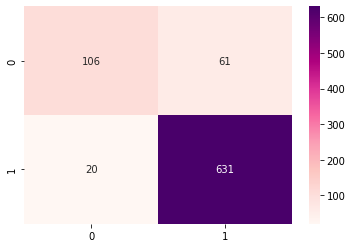
- 성능평가
ex) 다음 문장이 긍정인지 부정인지 예측하시오.
- 'amazing food! highly recommmended'
- 'shit food, made me sick'
| # 쌤 풀이 new_data = np.array(['amazing food! highly recommmended', 'shit food, made me sick']) X_new = vec.transform(new_data) X_new = X_new.toarray() classifier1.predict(X_new) |

| # 밑은 내 풀이 a = ['amazing food! highly recommmended'] b = ['shit food, made me sick'] new_data = np.array(a) X = vec.transform(new_data) classifier.predict(X) new_data2 = np.array(b) new_data2.reshape(1,1) X = vec.transform(new_data2) classifier.predict(X) |


ex) 서포터 백터 머신으로 인공지능을 만들어보세요.

| from sklearn.svm import SVC clalssifier3 = SVC(kernel = 'linear',random_state=7) clalssifier3.fit(X_train,y_train) y_pred3 = clalssifier3.predict(X_test) confusion_matrix(y_test,y_pred3) accuracy_score(y_test,y_pred3) sns.heatmap(confusion_matrix(y_test,y_pred3), annot= True, cmap = 'RdPu', fmt = '.0f') plt.show() clalssifier3.predict(X_new) |

'Python-머신러닝' 카테고리의 다른 글
| 범죄율 예측: pd.to_datetime(), dt.weekday, (0) | 2022.05.15 |
|---|---|
| 가격 예측 알고리즘: Facebook Prophet (0) | 2022.05.15 |
| 나이브 베이즈(Naive Bayes) 및 구글 코랩( Colab), Word Cloud2 (0) | 2022.05.15 |
| 실습 및 피쳐스케일링에서 원래 값으로 되돌리기, inverse_transform() (1) | 2022.05.15 |
| Count Vectorizing 카운트 벡터라이징: CountVectorizer() (0) | 2022.05.15 |



