반응형
- 문장을 원핫인코딩의 형식으로 하나씩 갯수를 표시하는 것을 count라고 하고
- 문자를 숫자로 바꾸는 걸 vectorizing이라고 함.
-> 이 두개를 합쳐서 count vectorizing이라고 함
규칙:
1. 모든 리뷰에 나온 단어를 뽑아서 알파벳 순서로 정렬
2. 정렬한 순서대로 컬럼을 나눈다.
3. 해당 리뷰에 쓰인 위치에 나온 단어만,
| from sklearn.feature_extraction.text import CountVectorizer vec = CountVectorizer() count_vec= vec.fit_transform(df['verified_reviews']) |
ㄴ 행렬
vec.fit_transform()
ㄴ fit : 모든 리뷰의 단어를 다 뽑아서 정렬해서 컬럼으로 뽑아라.
ㄴ transform: 컬럼 다 뽑았으면, 쓰인 위치별로 숫자로 표시 해라
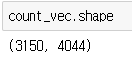
| review_array = count_vec.toarray() |
ㄴ 넘파이 형식으로 바꿔준다.

- 넘파이의 행렬의 데이터에 억세스 하는 방법
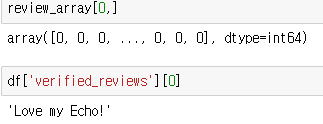
ㄴ 위의 문장을 숫자로 바꾼 것.
- 데이터 비주얼라이징
ㄴ 리뷰 길이와 별점의 관계를 히트맵으로 나타내세요.

1. apply 함수 이용방법
ㄴ apply안에 적을 함수 안에, 적용하라.
| df['verified_reviews'].apply(len) |

2. 문자열로 인식하는 방법
| df['len'] = df['verified_reviews'].str.len() |

| sb.scatterplot(data = df, x= 'len', y ='rating') plt.show() |

| plt.hist2d(data = df, x = 'len',y = 'rating', cmin = 0.5, cmap = 'viridis_r') plt.colorbar() plt.show() |

| df[['len','rating']].corr() |

반응형
'Python-머신러닝' 카테고리의 다른 글
| 나이브 베이즈(Naive Bayes) 및 구글 코랩( Colab), Word Cloud2 (0) | 2022.05.15 |
|---|---|
| 실습 및 피쳐스케일링에서 원래 값으로 되돌리기, inverse_transform() (1) | 2022.05.15 |
| Word Cloud 1 (0) | 2022.05.10 |
| Unsupervised Learning: Hierarchical Clustering (0) | 2022.05.10 |
| K-Means Clustering 실습 (0) | 2022.05.10 |



