ex) 다음과 같은 컬럼을 가지고 있는 데이터셋을 읽어서, 어떠한 고객이 있을때, 그 고객이 얼마정도의 차를 구매할 수 있을지를 예측하여, 그 사람에게 맞는 자동차를 보여주려 한다.
| - Customer Name - Customer e-mail - Country - Gender - Age - Annual Salary - Credit Card Debt - Net Worth (순자산) 예측하고자 하는 값 : - Car Purchase Amount |
| import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns |

car_df.columns

ex) 상관관계를 분석하기 위해, pairplot을 그려보자.
| sns.pairplot(data = car_df) plt.show() |

| sns.heatmap(data = car_df.corr(), annot = True, fmt = '.2f', vmin = -1, vmax =1, cmap = 'coolwarm', linewidths = 0.5) plt.show() |

ex) 학습을 위해 'Customer Name', 'Customer e-mail', 'Country', 'Car Purchase Amount' 컬럼을 제외한 컬럼만, X로 만드시오.
ㄴ 왜 'Country'는 제외하는가

ㄴ 각 나라별로 몇개의 데이터가 들어가있는지 확인
| car_df['Country'].value_counts() |

ㄴ 기껏해야 6개가 반복되는 게 3개밖에 없다.
ㄴ 원핫인코딩을 사용해야하는데, 그렇다면, 얼마의 컬럼이 늘어나는가, 그 컬럼이 과연 의미가 있는가
ㄴ 차 구매하는 데에 그렇게 큰 영향을 끼치지 않는 것으로 판단.
- X 및y 설정
| X = car_df.loc[:, 'Gender': 'Net Worth'] y = car_df['Car Purchase Amount'] |

ㄴ 스케일러는 무조건 2차원 진행, 현재 y는 1차원.
ㄴ 시리즈는 reshape이 없다.
- 피쳐스케일링
| from sklearn.preprocessing import MinMaxScaler scaler_X = MinMaxScaler() X= scaler_X.fit_transform(X) y = y.values.reshape(500,1) scaler_y = MinMaxScaler() y = scaler_y.fit_transform(y) |
- 트레이닝 모델(리니어 리그레션) 및 성능 평가
| from sklearn.model_selection import train_test_split X_train,X_test, y_train, y_test = train_test_split(X,y, test_size=0.25, random_state= 50) from sklearn.linear_model import LinearRegression regressor = LinearRegression() regressor.fit(X_train, y_train) y_pred = regressor.predict(X_test) error = y_test - y_pred (error**2).mean() |


원래값으로 돌리기
- transform 한 것을 원래로 되돌려라.
| scaler_y.inverse_transform(y_pred) |

ex) 유저가 앱을 통해서 데이터를 입력했습니다. 이 사람은 얼마정도의 차를 구매할 수 있을지 예측해서, 그 사람에게 맞는 차를 보여주려 합니다.
여자이고, 나이는 38살, 연봉은 78,000달러, 카드 빚은 15,000달러이고, 자산은 480,000달러입니다.

| new_data = np.array([0,38,78000,15000,480000]) |
- 우리가 예측 할때는, 피쳐스케일링을 하고 진행한것. 그러나 현재 입력하고자 하는 데이터는 가공되지 않은 날 것이므로, 가공이 필요하다.
- 예측 할 때도, 2차원으로 넣어줘야한다.

| new_data = new_data.reshape(1,5) |

| scaler_X.transform(new_data) |

ㄴ 피쳐스케일링을 진행해준다.
| y_pred = regressor.predict(new_data) |
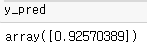
ㄴ 학습한 내용을 토대로 예측한다.

ex) RandomForest나 XGBoost를 이용하시오.
| from sklearn.ensemble import RandomForestRegressor # 수치 예측하는 거라, 리그레서 regressor = RandomForestRegressor(random_state= 50) # 학습 시킬 때 1차원으로 진행 regressor.fit(X_train,y_train.ravel()) y_pred = regressor.predict(X_test) ((y_test.ravel() - y_pred)**2).mean() # 1차원으로 만들게요. 그리고 1차원끼리 뺄셈을 할게요. # 그것이 오차입니다. # 이것이 MSE, 수치가 더 작을 수록 더 좋은 모델이다. |

'Python-머신러닝' 카테고리의 다른 글
| 댓글의 긍정/부정 인공지능 알고리즘(나이브 베이즈/서포터 백터 머신) (0) | 2022.05.15 |
|---|---|
| 나이브 베이즈(Naive Bayes) 및 구글 코랩( Colab), Word Cloud2 (0) | 2022.05.15 |
| Count Vectorizing 카운트 벡터라이징: CountVectorizer() (0) | 2022.05.15 |
| Word Cloud 1 (0) | 2022.05.10 |
| Unsupervised Learning: Hierarchical Clustering (0) | 2022.05.10 |



