Facebook Prophet
페이스북에서 만든 라이브러리, 타임시리즈 데이터를 처리하는 것.
| install : pip install fbprophet 위 에러 발생시 : conda install -c conda-forge fbprophet |
ex) 아보카도 가격 예측
ㄴ 데이터는 미국의 아보카도 리테일 데이터 입니다. (2018년도 weekly 데이터)
ㄴ 아보카도 거래량과 가격이 나와 있습니다.
ㄴ 컬럼설명:
| - Date - The date of the observation - AveragePrice - the average price of a single avocado - type - conventional or organic - year - the year - Region - the city or region of the observation - Total Volume - Total number of avocados sold - 4046 - Total number of avocados with PLU 4046 sold - PLU는 농산물 코드입니다 - 4225 - Total number of avocados with PLU 4225 sold - 4770 - Total number of avocados with PLU 4770 sold |
- import libraries
| import pandas as pd import numpy as np import matplotlib.pyplot as plt import random import seaborn as sns from fbprophet import Prophet |
ㄴ 구글 Colab에는 fbprophet 라이브러리가 이미 설치 되어있어서, 따로 설치가 필요없다.
- Colab에서 이용시
- 또한, 불러오고자 하는 파일이 구글드라이브 Colab Notebook 폴더에 업로드가 되어있어야한다.
| from google.colab import drive drive.mount('/content/drive') import os os.chdir('/content/drive/MyDrive/Colab Notebooks') |

- EDA(Exploratory Data Analysis): 탐색적 데이터 분석
df.describe() 와 비슷하다고 보면 됨
ㄴ 안에 어떤 데이터가 있고, 어떤 컬럼이 있는 등을 뜻함
ex) 날짜로 정렬하고, 날짜별로 가격이 어떻게 변하는지 간단하게 확인하시오(Plot이용)
| # 날짜로 정렬 df = df.sort_values(‘Date’) # 날짜별로 가격이 어떻게 변하는지 df_date = df.groupby(‘Date)[‘AveragePrice’].mean() |

| df_date.plot() plt.xticks(rotation = 30) plt.show() |

ex) 프로펫 분석을 위해 두개의 컬럼만 가져오고(‘Date,’AveragePrice’), ds와 y로 컬럼명을 셋팅하시오.
| avocado_prophet_df = df[['Date', 'AveragePrice']] avocado_prophet_df.columns = ['ds','y'] |
ㄴ .column 대신에 .rename을 이용해도 된다.
ㄴ 프로펫 라이브러리를 사용하려면, 컬럼이름을 바꿔야한다.
ㄴ 그런데, 컬럼이 많아도, 프로펫 라이브러리는 ds와 y라고 네이민 된 컬럼만 가져온다.
- 프로펫 이용하기
| prophet = Prophet() prophet.fit(avocado_prophet_df) # 365일치를 예측하시오. future = prophet.make_future_dataframe( periods = 365 ) forecast = prophet.predict(future) |
ㄴ # 1. 변수로 만들기: 메모리에 올려줘야한다.
ㄴ # 2. 데이터로 학습시키기
ㄴ # 3. 예측하고자 하는 기간을 정해서, 비어있는 데이터 프레임 만들기
- prophet.make_future_dataframe(periods = 365 )
ㄴ 디폴트 파라미터 freq = 'D',
ㄴ 비어있는 날짜를 만들어준다. 미래의 데이터
ㄴ # 4. 프로펫의 predict 함수에, 빈 데이터프레임을 넣어서, 예측 데이터를 채운다.

ㄴ yhat: 예측한 값
ㄴ 맨 뒤에 있는 컬럼(yhat)이 실제로 예측값임.
ex) 차트로 확인하시오.
| prophet.plot(forecast) plt.savefig('chart1.jpg') |
ㄴ 프로펫 자체적으로 plot함수가 있다.
ㄴ 차트가 버그가 생겨서 두개가 나오는데, savefig하면 하나만 나온다.
ㄴ 까만점이 없는 부분이 예측한값

| prophet.plot_components(forecast) plt.savefig('chart1.jpg') |
ㄴ 가격 및 주기성

ex) region이 west인 아보카도의 가격을 예측하시오
| avocado_df_sample = df.loc[df['region']== 'West',].copy() # 이 방법이 더 귀찮긴 하지만, 동작하긴 함 avocado_df_sample.rename(columns={'Date':'ds','AveragePrice':'y'}, inplace = True) # 어차피 프로펫은 ds하고 y만 가져옴. |
| prophet = Prophet() prophet.fit(avocado_df_sample) # 365일치, future1 = prophet.make_future_dataframe(periods=365) # 24주치 future2 = prophet.make_future_dataframe(periods=24, freq = 'W') forecast1 = prophet.predict(future1) forecast2 = prophet.predict(future2) |
| prophet.plot(forecast1) plt.savefig('chart1.jpg') |

| prophet.plot_components(forecast1) plt.savefig('chart4.jpg') |

| prophet.plot(forecast2) plt.savefig('chart1.jpg') |
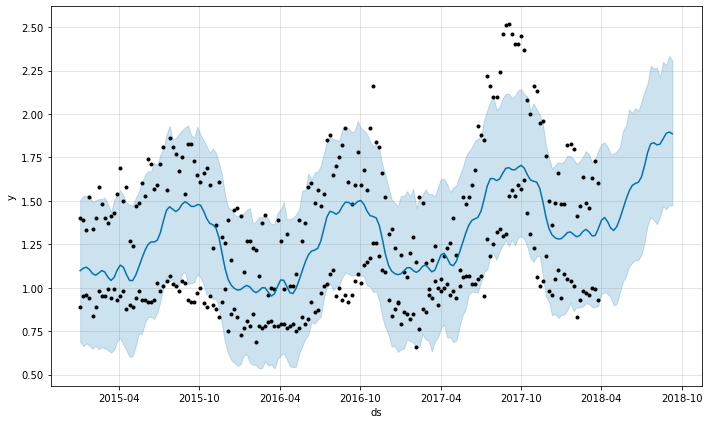
| prophet.plot_components(forecast2) plt.savefig('chart4.jpg') |

'Python-머신러닝' 카테고리의 다른 글
| 영화 추천 시스템 1/2 (0) | 2022.05.15 |
|---|---|
| 범죄율 예측: pd.to_datetime(), dt.weekday, (0) | 2022.05.15 |
| 댓글의 긍정/부정 인공지능 알고리즘(나이브 베이즈/서포터 백터 머신) (0) | 2022.05.15 |
| 나이브 베이즈(Naive Bayes) 및 구글 코랩( Colab), Word Cloud2 (0) | 2022.05.15 |
| 실습 및 피쳐스케일링에서 원래 값으로 되돌리기, inverse_transform() (1) | 2022.05.15 |



