반응형
Hierarchical Clustering
계층적 군집
K-means랑 다르다.
- 눈 사람 만들때, 눈덩이 굴리면, 커지듯이.
- 각 데이터별로 거리를 계산한다.
- 거리가 가까운것부터 계산 및 정렬한다. 그리고, 가장 가까운 것부터 묶는다.
ㄴ그것을 정리한 표가 Dendrogram이라고 한다.

ㄴ 그림처럼 하나씩 정리해나간다.
ㄴ 또한, 거리 길이가 y값이 된다. 가까울수록 y길이가 짧아지고, 길수록 y값이 커진다.


ㄴ 여기서 y값이 가장 긴 값을 택하여 그 절반의 값을 선으로 가로지른다.
ㄴ 가로지르는 선과 맞닿은 부분들을 k값으로 택한다.

ㄴ 해당 이미지는 맞닿은 점이 2개므로, k값을 2개로 택한다.
ㄴ 정답은 없다.
| import scipy.cluster.hierarchy as sch sch.dendrogram(sch.linkage(X,method='ward')) plt.title('Dendrogram') plt.xlabel('Customers') plt.ylabel('Euclidean Distances') plt.show() |

ㄴ y축이 제일 긴 그래프에 선을 그어보니, 5개의 점과 맞닿는다.
ㄴ 고로 k값은 5개로 정하겠다.
- Hierarchical Clustering 알고리즘 모델링
| from sklearn.cluster import AgglomerativeClustering hc = AgglomerativeClustering(n_clusters= 5) |
ㄴ 병합적 군집
ㄴ 방정식이 아니라, 거리계산이므로, AgglomerativeClustering 파라미터에는 random_state는 없다.
- 학습 및 예측
| y_pred = hc.fit_predict(X) |
- 분류를 완료했으니, 데이터 프레임에 새로운 컬럼으로 만들어준다.
| df['Group'] = y_pred |
- Grouping 정보 확인
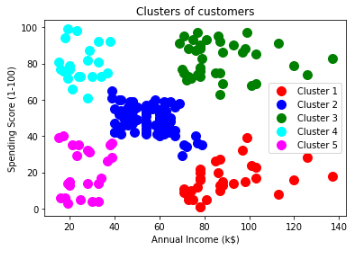
| plt.scatter(X.values[y_pred == 0, 0], X.values[y_pred == 0, 1], s = 100, c = 'red', label = 'Cluster 1') plt.scatter(X.values[y_pred == 1, 0], X.values[y_pred == 1, 1], s = 100, c = 'blue', label = 'Cluster 2') plt.scatter(X.values[y_pred == 2, 0], X.values[y_pred == 2, 1], s = 100, c = 'green', label = 'Cluster 3') plt.scatter(X.values[y_pred == 3, 0], X.values[y_pred == 3, 1], s = 100, c = 'cyan', label = 'Cluster 4') plt.scatter(X.values[y_pred == 4, 0], X.values[y_pred == 4, 1], s = 100, c = 'magenta', label = 'Cluster 5') plt.title('Clusters of customers') plt.xlabel('Annual Income (k$)') plt.ylabel('Spending Score (1-100)') plt.legend() plt.show() |
반응형
'Python-머신러닝' 카테고리의 다른 글
| Count Vectorizing 카운트 벡터라이징: CountVectorizer() (0) | 2022.05.15 |
|---|---|
| Word Cloud 1 (0) | 2022.05.10 |
| K-Means Clustering 실습 (0) | 2022.05.10 |
| Unsupervised Learning(비지도 학습): K-Means Clustering (0) | 2022.05.10 |
| non-linear : Decision Tree (0) | 2022.05.10 |



