실습: Breast Cancer Classification
| - 유방암진단 문제 : 양성이냐 악성이냐 예측 - 30 features are used, examples: - radius (반지름) - texture (조직) - perimeter (둘레) - area - smoothness (local variation in radius lengths) - compactness (perimeter^2 / area - 1.0) - concavity (오목함) - concave points (오목한 부분의 점) - symmetry (대칭) - fractal dimension ("coastline approximation" - 1) - 30 input features - Number of Instances: 569 - Class Distribution: 212 Malignant(악성), 357 Benign(양성) - Target class: - Malignant(악성) - Benign(양성) |
데이터는 라이브러리에 있다.
| # import libraries import pandas as pd # Import Pandas for data manipulation using dataframes import numpy as np # Import Numpy for data statistical analysis import matplotlib.pyplot as plt # Import matplotlib for data visualisation import seaborn as sns # Statistical data visualization # %matplotlib inline from sklearn.datasets import load_breast_cancer cancer = load_breast_cancer() |
ㄴ 항상 cpu에게 일 시키려면 메모리에 올려놓아야한다.
type(cancer)
cancer.keys()
->
dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename'])
cancer['data']
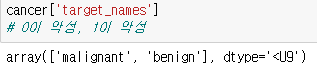
cancer['target_names']
cancer['feature_names']
# 각각의 데이터 컬럼

cancer['data']
# 상기와 매칭

cancer['data'].shape
->
(569, 30)
cancer['feature_names'].shape
->
(30,)
- np.c_ 넘파이끼리 데이터를 옆으로 합쳐준다.
ㄴ 넘파이끼리 행의 갯수가 같으면, 옆에 컬럼을 바로 붙이는 방법
ㄴ 컨캣의 약자
| my_data = np.c_[cancer['data'],cancer['target']] my_columns = np.append(cancer['feature_names'],'target') df = pd.DataFrame(data = my_data, columns = my_columns) |
- np.append 함수는 넘파이에, 데이터를 추가할때 사용
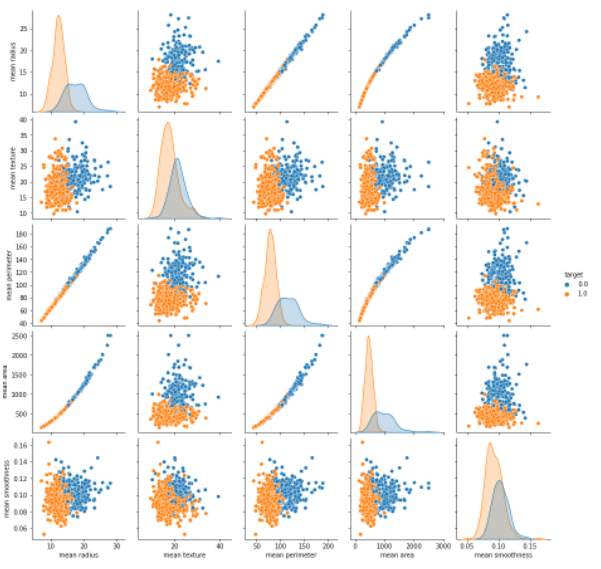
ex) pairplot을 이용해서, 각 컬럼의 관계를 파악해보세요. 상관계수도 보여주세요.
ㄴ mean radius, mean texture, mean perimeter, mean area, mean smoothness, target, 6개 컬럼만 plarplt과 상관계수를 구하세요.
| import seaborn as sns sns.pairplot(data = df, hue = 'target', vars = ['mean radius', 'mean texture', 'mean perimeter', 'mean area', 'mean smoothness']) plt.show() |
ㄴ target의 컬럼을 좌표 위에 색을 입힌다.
| df[['mean radius', 'mean texture','mean perimeter', 'mean area', 'mean smoothness']].corr() # target 컬럼에는 0과 1로 데이터가 있는데, # 0은 몇개고, 1은 몇개인지 차트로 나타내시오. df['target'].value_counts() sns.countplot(data = df, x = 'target') plt.show() # 새로운 차트, # mean area 컬럼과 mean smoothness의 관계를 차트로 나타내시오 # target 컬럼은 색깔로 표시하세요. sns.scatterplot(data = df, x = 'mean area', y = 'mean smoothness',hue = 'target') plt.show() |
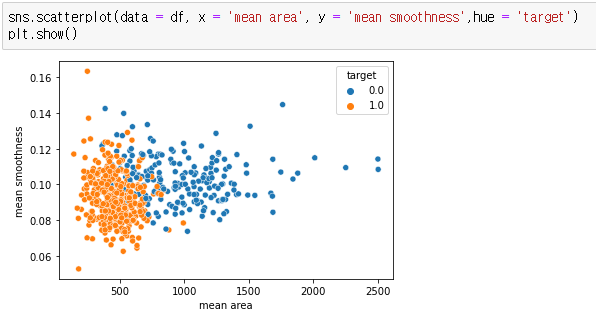
| plt.figure(figsize = (20,10)) sns.heatmap(data = corr_result, annot = True, fmt = '.1f', vmin = -1, vmax = 1, cmap = 'coolwarm', linewidths=0.5) # 최소값이 -1이고, 맥스값을 정해준다. # 빨간색은 비례관계, 파란색은 반비례 plt.show() |
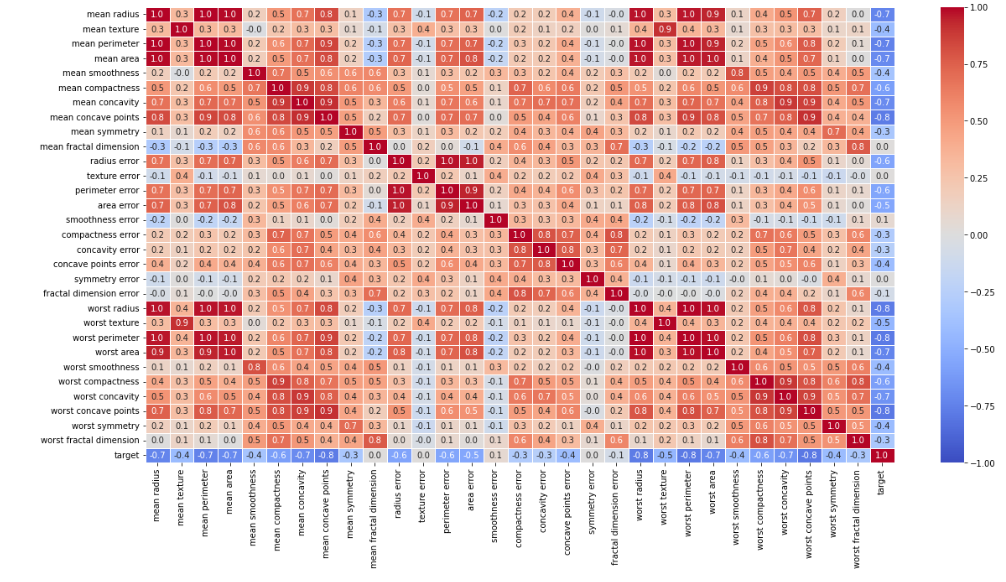
ㄴ 대각선은 대칭이므로, 대각선 밑부분만 본다.
ㄴ 0이 악성, 1이 양성
ㄴ 파란색이 진할 수록, 더욱히 악성과 관계가 있다.
- 모델링
| df.isna().sum() y = df['target'] X = df.loc[:,: 'worst fractal dimension'] # X = df.iloc [ : , :-2+1] from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler() X = scaler.fit_transform(X) from sklearn.model_selection import train_test_split X_train,X_test,y_train, y_test = train_test_split(X,y,test_size = 0.2, random_state= 3) from sklearn.svm import SVC classifier = SVC(kernel='linear',random_state=3) classifier.fit(X_train,y_train) classifier2 = SVC(kernel= 'rbf',random_state=3) classifier2.fit(X_train,y_train) y_pred = classifier.predict(X_test) y_pred2 = classifier2.predict(X_test) from sklearn.metrics import confusion_matrix,accuracy_score confusion_matrix(y_test,y_pred) accuracy_score(y_test,y_pred) confusion_matrix(y_test,y_pred2) accuracy_score(y_test,y_pred2) |
'Python-머신러닝' 카테고리의 다른 글
| non-linear : Decision Tree (0) | 2022.05.10 |
|---|---|
| 실습2: 하이퍼 파라미터, 좋은 모델 조합 도출 방법 : Grid Search (0) | 2022.05.10 |
| SVM: Support Vector Machine (0) | 2022.05.08 |
| K-Nearest Neighbors 및 K값 (0) | 2022.05.08 |
| Logistic Regression 실습: 사람이 데이터를 잘 봐야한다. (0) | 2022.05.08 |



