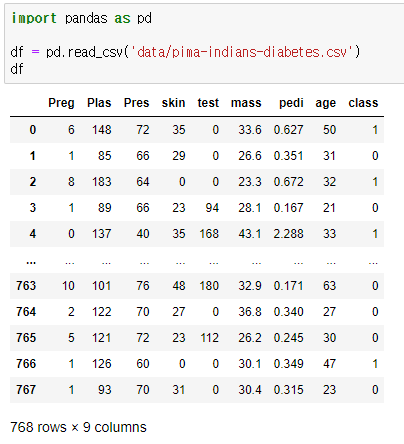
ex) pima-indians-diabetes.csv 파일을 읽어서, 당뇨병을 분류하는 모델을 만드시오.
ㄴ 컬럼 정보
| Preg=no. of pregnancy Plas=Plasma Pres=blood pressure skin=skin thickness test=insulin test mass=body mass pedi=diabetes pedigree function age=age class=target(diabetes of not, 1:diabetic, 0:not diabetic) |
- Nan 체크
| df.isna().sum() |
- X와 y 설정
| X = df.loc[:, : 'age'] # df.iloc[: , 0: -2+1] y=df['class'] |
- 이상한 점 발견
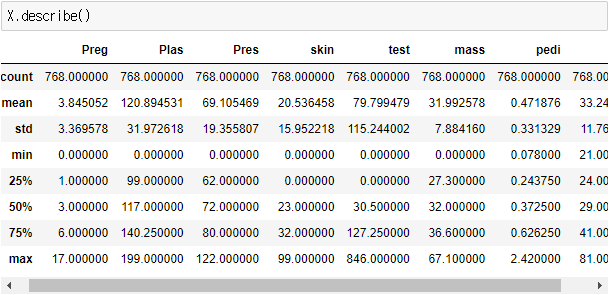
ㄴ 혈압이 0이면 죽은 사람 아니냐, 등의 최소가 0인 값이 있다는 것이 좀 이상한 이야기 인것 같다.
- 정확한 인공지능을 만들기 위해서는, 사람이 데이터를 잘 봐야한다.
| df.loc[df['Pres']==0,].shape df.shape df.loc[df['skin']==0,].shape |

- 해당 상황은 데이터가 비어있어야하는 데, 비어있는 내용을 0으로 넣었을 수도 있다.
- 데이터가 비어있으면, Null이라고 표시되며, 비어있도록 놔두는 것이다.
ㄴ 판다스의 장점은 비어있는 데이터는 Nan로 처리해준다.
ㄴ 백앤드 개발자일 떄, 데이터가 없으면 그냥 없는대로 넘기면 좋다.
- 0이라고 되어있는 걸 Nan으로 바꿔주는 작업을 해야한다.
- 최소값이 0이라고 되어있는 컬럼이 Preg, Plas, Pres, skin, test, mass.
- 데이터 프레임에 replace라는 함수가 있다.
ㄴ문자열에 쓰이는 replace와는 다른 함수이다.
| import numpy as np X.loc[:,'Plas': 'mass'] = X.loc[:,'Plas': 'mass'].replace(0, np.nan) |


- Nan의 데이터가 카운트 되었다.
- Nan 처리 방법
ㄴ 첫번째 전략: Nan 없애는 전략
ㄴ 두번째 전략: Nan을 다른 값으로 채우는 전략
- 두번째 전략을 채택하여, Nan의 값을 평균값으로 채워보자.

| X = X.fillna(X.mean()) |

- 피쳐스케일링: 정규화로 진행해본다.
| from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler() X_scaled = scaler.fit_transform(X) X_scaled |
- 트레이닝셋과 테스트셋으로 나눈다.
| from sklearn.model_selection import train_test_split X_train,X_test, y_train, y_test = train_test_split(X_scaled,y,test_size = 0.2, random_state= 0) |
- 모델링
| from sklearn.linear_model import LogisticRegression classifier = LogisticRegression() classifier.fit(X_train,y_train) |
- 컴퓨전 매트릭스로 검증
| y_pred = classifier.predict(X_test) y_test.values from sklearn.metrics import confusion_matrix,accuracy_score, classification_report cm = confusion_matrix(y_test, y_pred) |
ㄴ y_test.values: 시리즈니까, 넘파이로 만들기
ㄴ cm = confusion_matrix(실제값, 예측값)
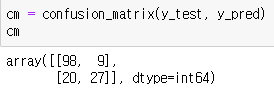
- 정확도
accuracy_score(y_test,y_pred) print(classification_report(y_test,y_pred)) |

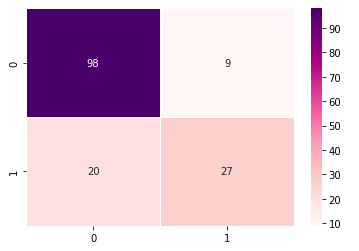
- 그래프로 만들기
| import seaborn as sb import matplotlib.pyplot as plt sb.heatmap(data = cm, cmap = 'RdPu', linewidths=0.5, annot = True) plt.show() |
'Python-머신러닝' 카테고리의 다른 글
| SVM: Support Vector Machine (0) | 2022.05.08 |
|---|---|
| K-Nearest Neighbors 및 K값 (0) | 2022.05.08 |
| Logistic Regression 로지스틱 회귀: Confusion Matrix, accuracy_score(), classification_report() (0) | 2022.05.08 |
| linear regression 실습 + 미지수, 상수값: coef_, intercept_ (0) | 2022.05.08 |
| Multiple Linear Regression (0) | 2022.05.08 |



