반응형
K-Nearest Neighbors


빨간색이냐 녹색이냐 두개로 분류하는 문제를 해결할 것.
- K란: 기존 데이터와 신규데이터의 거리를 계산한다. 계산해서 정렬을 한다.
ㄴ 내 주위에 몇개의 이웃을 확인해 볼것인가를 결정한다.
ㄴ 가장 거리를 가까운 것부터 먼 순으로,
- K를 5로 정하면, 신규 데이터와 가장 가까운 데이터 수를 5개로 묶어서 빨간게 더 많으면, 빨간색으로 분류한다.
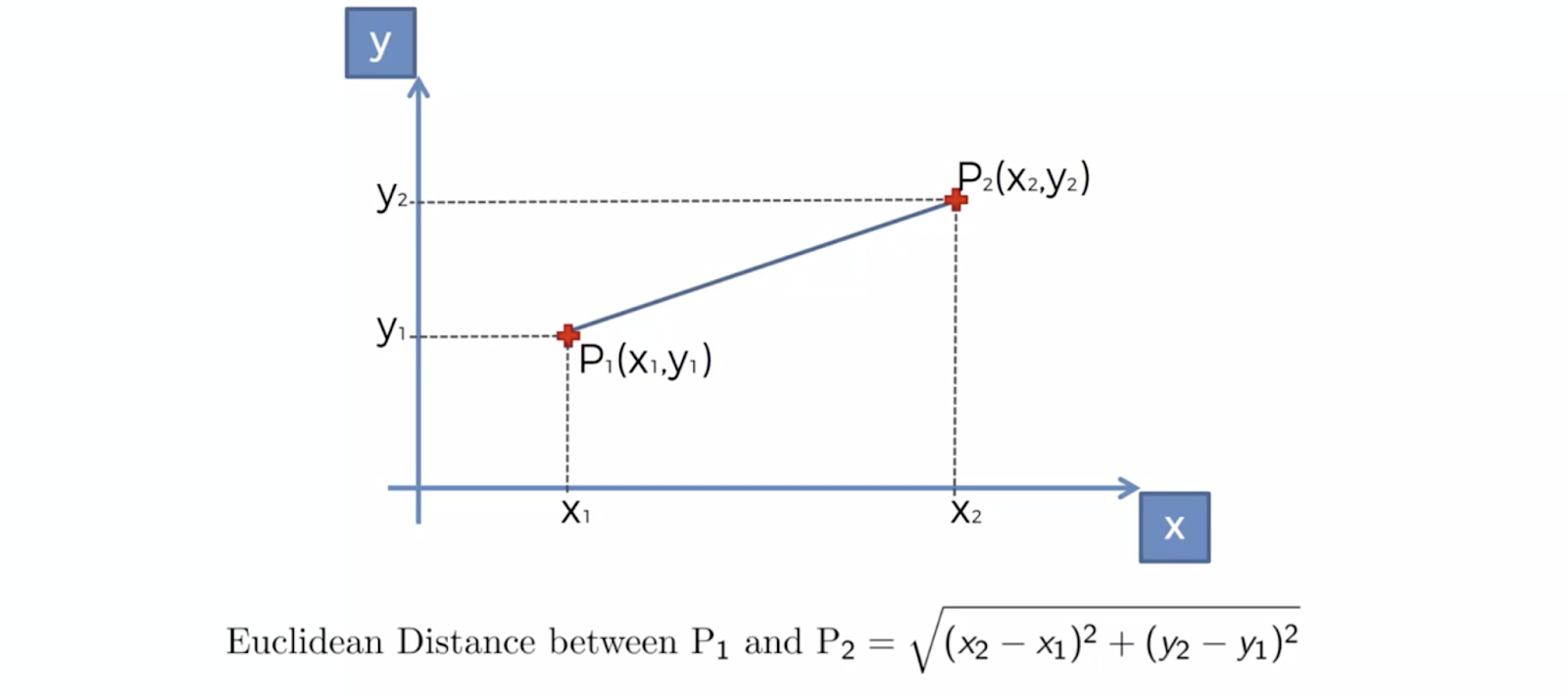
- 거리 계산은 피타고라스 정리로 한다.
ㄴ이런 거리를 Euclidean 거리라고 함.

- Euclidean 거리에 의해서, 가장 가까운 K개의 이웃을 택한다.
- 카테고리의 숫자가 많은 쪽으로, 새로운 데이터의 카테고리를 정해버린다.

| import numpy as np import pandas as pd import matplotlib.pyplot as plt X = df.loc[: , 'Age' : 'EstimatedSalary'] y = df['Purchased'] from sklearn.preprocessing import StandardScaler scaler = StandardScaler() X = scaler.fit_transform(X) from sklearn.model_selection import train_test_split X_train,X_test, y_train, y_test = train_test_split(X,y,test_size = 0.2, random_state= 0) |
- 모델링: KNN을 분류하는 모델
| from sklearn.neighbors import KNeighborsClassifier classifier = KNeighborsClassifier(n_neighbors=11) |
- K값 디폴트 값이 5, 홀수여야한다. 짝수로 나오다가 5:5면 어떡해
- 훈련
| classifier.fit(X_train,y_train) |
- 검증
| y_pred = classifier.predict(X_test) from sklearn.metrics import confusion_matrix,accuracy_score cm = confusion_matrix(y_test,y_pred) |

- 정확도
| accuracy_score(y_test,y_pred) |

반응형
'Python-머신러닝' 카테고리의 다른 글
| 실습: 넘파이 데이터 옆으로 합치기, 데이터 추가: np.c_, np.append() (0) | 2022.05.10 |
|---|---|
| SVM: Support Vector Machine (0) | 2022.05.08 |
| Logistic Regression 실습: 사람이 데이터를 잘 봐야한다. (0) | 2022.05.08 |
| Logistic Regression 로지스틱 회귀: Confusion Matrix, accuracy_score(), classification_report() (0) | 2022.05.08 |
| linear regression 실습 + 미지수, 상수값: coef_, intercept_ (0) | 2022.05.08 |



