반응형
SVM: Support Vector Machine
- 새로운 데이터가 들어왔을 때, 기존 데이터와의 거리를 선으로 분류하자.
- 분류선에 가장 가까운 데이터들을, 가장 큰 마진(margin)으로 설정하는 선으로 결정하자.
- 분류선을 Maximum Margin Classifer라고 한다.
ㄴ가장 좋은 선은 가장 가까이 위치하고 있는 데이터, 그런 데이터를 서포트 벡터라고 한다.
- SVM은 다른 머신러닝 알고리즘과 비교해서 무엇이 특별한가?
ㄴ 사과인지 오렌지인기 분석하는 문제
ㄴ 일반적인 사과와 오렌지들은, 클래서파이어에서 멀리 분포한다.

ㄴ 정상적이지 않은 것들, 즉 구분하기 힘든 부분에 있는 것들은 클래서파이어 근처에 있게 되며,
ㄴ 이 데이터들이 레이블링 되어 있으므로, Margin을 최대화 하여 분류하기 때문에, 특이한 것들까지 잘 분류하는 문제에 SVM 이 최고다.


- Nan 확인
- X, y 설정
- 피쳐스케일링
- X,y 분리
- 모델링
- 학습
ㄴ x를 가지고 학습을 시키는 데, ndim 하면, 몇차원, 컬럼의 갯수라는 소리
- 성능 평가
| df.isna().sum() X = df.iloc[ : , 2:3+1] y = df['Purchased'] from sklearn.preprocessing import StandardScaler scaler = StandardScaler() X = scaler.fit_transform(X) from sklearn.model_selection import train_test_split X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=0) from sklearn.svm import SVC classifier = SVC(kernel= 'linear', random_state=3) classifier.fit(X_train,y_train) y_pred = classifier.predict(X_test) from sklearn.metrics import confusion_matrix,accuracy_score cm = confusion_matrix(y_test, y_pred) accuracy_score(y_test,y_pred) |
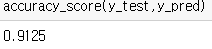
svc(kernel = ‘linear’...
kernel{‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’} or callable, default=’rbf’
커널이 있는데, 거기서 제일 성능이 좋은 걸로 하나씩, 바꿔가면서 실험을 해보라. 실험 결과/성능 평가를 가지고 인공지능 실무에 임하여라.
- 다른 커널 사용时
| classifier2 = SVC(kernel= 'rbf',random_state=0) classifier2.fit(X_train, y_train) y_pred2 = classifier2.predict(X_test) cm2 = confusion_matrix(y_test,y_pred2) accuracy_score(y_test,y_pred2) |

반응형
'Python-머신러닝' 카테고리의 다른 글
| 실습2: 하이퍼 파라미터, 좋은 모델 조합 도출 방법 : Grid Search (0) | 2022.05.10 |
|---|---|
| 실습: 넘파이 데이터 옆으로 합치기, 데이터 추가: np.c_, np.append() (0) | 2022.05.10 |
| K-Nearest Neighbors 및 K값 (0) | 2022.05.08 |
| Logistic Regression 실습: 사람이 데이터를 잘 봐야한다. (0) | 2022.05.08 |
| Logistic Regression 로지스틱 회귀: Confusion Matrix, accuracy_score(), classification_report() (0) | 2022.05.08 |



