| import numpy as np import matplotlib.pyplot as plt import pandas as pd df = pd.read_csv('data/Data.csv') |

ㄴ 이 데이터로 내가 뭘 할건데?
ㄴ 위 데이터로 우리 쇼핑몰에서 물건을 살 것 같냐, 못살것 같냐라는 구매여부 인공지능을 만들면 될 것 같다.
Nan 처리
ㄴ 학습을 시킬 때, 바로 Nan이 있으면 바로 에러가 나온다.
ㄴ 문제를 확인하면, NaN 있는지 확인해야한다.
ㄴ 우선적으로 Nan을 처리해야한다.
ㄴ 처리방법은: 삭제하거나, 다른 것으로 채우거나.
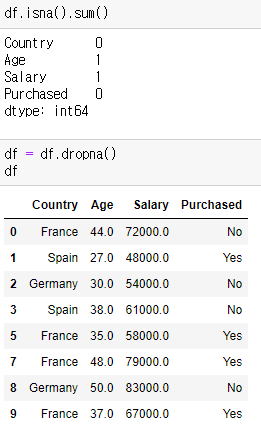
X, Y 데이터 분리: 즉 학습할 변수와 레이블링 변수로 분리
ㄴ 내가 예측하려고 하는 컬럼은 Purchased 컬럼, 그럼 이걸 y,
ㄴ 나머지는 x인데, 그리고, 필요없는 컬럼은 제외한다.
| X = df.loc[ : , 'Country':'Salary' ] y = df['Purchased'] |
ㄴ 1차원이라서 소문자로 쓴다. y

문자열 처리
ㄴ 컴퓨터는 숫자로 처리한다.
ㄴ 문자열 같은 경우, 컴퓨터는 못 읽는다. 숫자가 아닌 데이터 중에서, 카테고리로 판단되는 데이터는, 고로 숫자로 바꿔줘야한다.
ㄴ 먼저 몇개인지 파악 필요

- 먼저, 해당 컬럼이 카테고리컬(분류를 할 수 있는) 데이터인지 확인한다.
- 카테고리컬 데이터이면, 데이터를 먼저 정렬한다.

- 정렬한 후의 문자열을, 앞에서부터 0으로 숫자를 하나씩 매겨준다.
France: 0
Germany: 1
Spain :2
위처럼 설정하는 건 어떨까
문자열 처리1: Lable Encoding (레이블 인코딩)
ㄴ 카테고리컬 데이터도 사람들이 학습을 시켜봤더니, 레이블 인코딩이 3개 이상이면, 학습이 잘 안된다.
ㄴ 2개까진 잘됨
ㄴ 카테고리컬 데이터가 2개일 때는 레이블 인코딩으로 한다.
from sklearn.preprocessing import LabelEncoder,OneHotEncoder from sklearn.compose import ColumnTransformer |
ㄴ preprocessing 전처리: 학습시키기 전에 처리함.
레이블 인코딩 하는 방법
1. 변수 먼저 만들기 = 메모리에 만들기
2. 변환 시킴, 그러면 대체되어 저장이 된다.
ex)
| encoder = LabelEncoder() X['Country']== encoder.fit_transform(X['Country']) |
ex)
| encoder_y = LabelEncoder() y = encoder_y.fit_transform(y) |
ㄴ fit: 유니크한 것부터 찾아라

문자열 처리2: OneHot Encoding (원핫 인코딩)
| France | Germany | Spain |
| 1 | 0 | 0 |
| 0 | 0 | 1 |
| 0 | 1 | 0 |
| 0 | 0 | 1 |
| 1 | 0 | 0 |
…등등…
- 위 같은 처리방법이 원핫 인코딩이라고 함.
- 첫번째 데이터에 핫이 하나 들어있다. 두번째~다섯번째도, 오직 0과 1로 처리한다.
- 사람들은 카테고리컬 데이터가 3개 이상일 때는, 레이블 인코딩으로 학습시키면, 학습이 잘 되지 않는 다는 것을 알아냈다.
- 따라서, 3개 이상의 카테고리컬 데이터는,
- One-Hot Encoding(원 핫 인코딩)을 이용해야, 성능이 좋아진다.
원핫 인코딩 하는 방법:
| ct = ColumnTransformer([('encoder',OneHotEncoder(),[0])], remainder= 'passthrough') |
ㄴ 첫번째 파라미터는 리스트, 두번째는 remainder =
- [0] 이라고 쓴 이유는?
ㄴ X에서 원핫인코딩할 컬럼이 컴퓨터가 매기는 인덱스로 0이기 떄문에
ㄴ 즉, 원핫 인코딩할 컬럼의 인덱스를 써주면, 변환시켜준다.
- 만약 원핫 인코딩할 컬럼이 2개면, 해당 컬럼의 인덱스를 리스트안에 [0,2] 이런식으로 적어주면 된다.
- 결과는, 원핫 인코딩한 컬럼이 행렬의 맨 왼쪽에 나온다.

- CPU가 X를 인코더, 원핫인코더하고, 대괄호 0, 내가 준 행렬의 첫번째 컬럼만 원핫인코딩 해달라는 뜻
- remainder='passsthrough'는 나머지 컬럼은 그냥 원래있는 값 그대로 통과시켜라 라는 뜻
- 먼저 고유의 값을 찾아낸다음, 그만큼의 컬럼 수로 늘어난다 (3개로 늘어난다.)
- [1.0e+00, 0.0e+00, 0.0e+00, 4.4e+01, 7.2e+04],
ㄴ 1.0e+00 -> 1이라는 뜻
ㄴ 머신러닝은 플롯으로 처리한다.
ㄴ 뒤에는 건들지 말라고 했으니, 뒤의 컬럼의 값은 그대로 놔둔다.
Feature Scaling
(자세한 설명은 ‘노멀라이징/Feature Scaling’글 참고)
- 피쳐 스케일링도, X 따로 ,y 따로 한다.
- StandardScaler(), MinMaxScaler() 둘 다 사용하면 안된다.
ㄴ 둘 중에 하나를 사용하라, 성능은 크게 차이가 없다.
| m_scaler = MinMaxScaler() X = m_scaler.fit_transform(X) X |

- y도 피쳐스케일링을 해야하는데,
ㄴ 이미, 0과 1로만 데이터가 구성되어 있으면, 피처스케일링을 할 필요가 없다.
ㄴ 따라서 y는 그냥 냅두면 된다.
'Python-머신러닝' 카테고리의 다른 글
| linear regression 실습 + 미지수, 상수값: coef_, intercept_ (0) | 2022.05.08 |
|---|---|
| Multiple Linear Regression (0) | 2022.05.08 |
| Linear Regression (0) | 2022.05.08 |
| Dataset의 Training용과 Test 용: X_train,X_test,y_train,y_test (0) | 2022.05.06 |
| [Python] 머신러닝 개념 (0) | 2022.05.06 |



