머신러닝
- 용어 및 설명 참고: https://www.youtube.com/watch?v=KDrys0OnVho
인공지능을 머신러닝 시킨다는 뜻은,
-> 컴퓨터가 방정식을 채우고, 컴퓨터가 미지수를 데이터로 찾아가는 과정임.
-> 데이터가 적으면 미지수를 어설프게 찾아낸다.
-> 데이터가 많으면 미지수의 정교하게 찾아낸다 = 정확도가 올라간다.
인공지능을 왜 만드냐
무언가를 예측하거나, 예측한 것을 이용해서 회사는 수익을 더 극대화 하기 위함.
- Supervised, Unsupervised
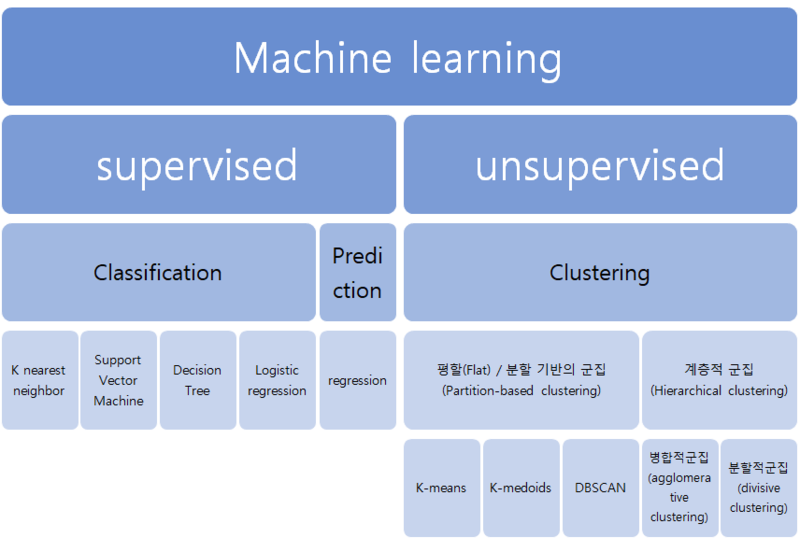
Unsupervised Learning
- 그룹정보를 불러오는 방법, 정답은 나도 모르고 컴퓨터도 모른다.
- 비슷한 부류/성향의 고객들로 묶어달라.
- 컴퓨터가 계산해서, 그룹정보라는 컬럼을 새로 만든다.
supervised Learning
| 우리는 Iris꽃의 꽃잎의 길이와 넓이, 꽃받침의 길이와 넓이 데이터를 가지고 있다. 이 데이터들을 가지고, Iris 꽃 (붓꽃) 의 품종을 분류할 수 있는 분류기를 만든다. 따라서, 새로운 꽃잎의 길이와 넓이, 꽃받침의 길이와 넓이에 대한 데이터를 입력하면, 이 붓꽃이 어떤 품종인지 분석이 가능하다. 이렇게 분류할 수 있는 분류기(classifier) 를 만들기 위해서는 데이터가 필요하며, 학습을 하기 위해서는, 데이터 뿐만 아니라, 품종이라는 결과를 학습 시키기 위해서, 데이터와 매핑된 품종 데이터도 함께 필요하다. 즉, 품종에 대한 데이터를 Lable 이라고 한다. 즉 이러한 레이블이 있는 데이터를 학습시키는 것이 지도학습이다. |
ㄴ 레이블이 있는 데이터를 학습시키는 것이 지도학습이다.
Regression(회귀) 과 Classification(분류)
Regression
ㄴ 수치 예측
- 예 ) 어떤 사람의 교육수준, 나이, 주거지를 바탕으로 연간 소득을 예측하는 것
- 예 ) 옥수수 농장에서 전년도 수확량과 날씨, 고용 인원수 등으로 올해 수확량을 예측하는 것
Classifiation
- 예) 웹사이트가 어떤 언어로 되어있는가
- 예) 사진을 보고, 고양이 인지 강아지 인지, 소인지 분류
Training 과 Test
- 훈련이란, 데이터를 입력하고, 그 결과인 레이블이 나오도록 만드는 과정.
ㄴ 즉, 데이터와 레이블을 통해 학습을 시키는 과정
- 테스트란, 학습이 완료된 분류기에, 학습에 사용하지 않은 데이터를 넣어서, 정답을 맞추는지 확인하는 작업

sklearn 설치
ㄴ 아나콘다에 설치되어 있으며, 만약 설치가 안되었으면 다음으로 설치함
ㄴ $ conda install -c conda-forge scikit-learn
| import numpy as np import matplotlib.pyplot as plt import pandas as pd df = pd.read_csv('data/Data.csv') |

ㄴ 이 데이터로 내가 뭘 할건데?
ㄴ 위 데이터로 우리 쇼핑몰에서 물건을 살 것 같냐, 못살것 같냐라는 구매여부 인공지능을 만들면 될 것 같다.
'Python-머신러닝' 카테고리의 다른 글
| linear regression 실습 + 미지수, 상수값: coef_, intercept_ (0) | 2022.05.08 |
|---|---|
| Multiple Linear Regression (0) | 2022.05.08 |
| Linear Regression (0) | 2022.05.08 |
| Dataset의 Training용과 Test 용: X_train,X_test,y_train,y_test (0) | 2022.05.06 |
| Nan 처리, 문자열 처리(레이블/원핫 인코딩): LabelEncoder,OneHotEncoder, ColumnTransformer (0) | 2022.05.06 |



