반응형
Dataset을 Training용과 Test 용으로 나눈다.
X_train,X_test,y_train,y_test = train_test_split(X,y, test_size = 0.2, random_state=3 )
ㄴ 파라미터 순서 바뀌면 안된다.
ㄴ 전세계 변수명 규칙이 같다
X_train
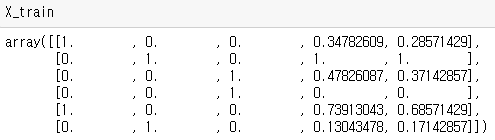
ㄴ 넘파이 어레이 4개,
y_train

ㄴ 첫번째 데이터는 1이다. 두번째 데이터는 0이다.
X_test: X 시험용

y_test: y 시험용

random_state:
ㄴ random.seed()와 random_state는 같은 의미이다.
ㄴ 랜덤으로 나오는 패턴을 같다라는 뜻 = 똑같은 환경으로 개발할 수 있다라는 뜻
X_train,X_test, y_train, y_test = train_test_split(X,y,test_size = 0.2, random_state= 0)
ㄴ> 기본적으로 여기서는 데이터를 랜덤으로 가져와서, 훈련 하고, 나머지 값을 테스트 한다는 뜻
ㄴ> State가 같으면, 랜덤값 순서가 같다.
인공지능을 학습시키기 전에, 먼저 우리가 해야할일
| - 처음에 데이터셋을 가져옴.csv를 판다스로 불러옴 - 무슨 인공지능을 만들지 우리가 먼저 판단. - 비어있는 데이터를 먼저 처리 - 나머지 데이터로 X와 Y로 분리, - 내가 예측하고 싶은 부분을 y, 나머지를 x - 인코딩: 문자 데이터를 숫자로 변환하는 작업 (카테고리컬 데이터인지 확인하고, 3종류 이상이면 원핫인코딩, 2종류이면 레이블인코딩) - 범위 맞춰주는 작업 시작 - 표준화/정규화의 방식 두가지가 있음 - 둘 중에 하나 선택해서 하면 된다. - 이미, 0과 1로만 데이터가 구성되어 있으면, 피처스케일링을 할 필요가 없다. - Train/Test 각 x와 y로 나누어서, 4개의 구역으로 나눈다. - 성능측정 |
.
반응형
'Python-머신러닝' 카테고리의 다른 글
| linear regression 실습 + 미지수, 상수값: coef_, intercept_ (0) | 2022.05.08 |
|---|---|
| Multiple Linear Regression (0) | 2022.05.08 |
| Linear Regression (0) | 2022.05.08 |
| Nan 처리, 문자열 처리(레이블/원핫 인코딩): LabelEncoder,OneHotEncoder, ColumnTransformer (0) | 2022.05.06 |
| [Python] 머신러닝 개념 (0) | 2022.05.06 |



