노멀라이징:
ㄴ 노멀라이징: 데이터 노멀라이징 하는 이유는, 각각의 레인지를 통일하여, 해석하기 쉽게 하기 위함입니다.
- 학습에 들어갈 데이터는 사람이 만든다. 학습은 컴퓨터가 한다.
- 머신 러닝에 제일 많이 쓰이는 것이, 제일 많이 쓰는것이 퍼센테이지,
- “~률”이 범위를 통일 시켜주는 것, 0에서 100으로 통일
ㄴ 각 건수에 대해서는 범위가 각 다르기 때문에(1~10과 100과 1000) 절대 비교가 불가능하다.
ㄴ 인공지능도 범위가 통일되어있지 않은 상태에서 학습을 시키면, 학습이 안된다.
- 인공지능에서는 특징이라고 하고,
- 데이터 분석에서는 컬럼이라고 한다.

- 학습을 시킬 때는 퍼센테이지가 좋지만, 이는 사람이 보기 편하기 위함이라, 이를 컴퓨터에 응용하면, 계산을 잘 못한다.
- Feature Scaling 우리가 다 알고 있는 건 퍼센테이지
- 머신러닝, 학습시킬 때는 상기 두가지 방법이 상기 이미지와 같이 두가지
ㄴ 표준화: 각 컬럼의 평균과, 컬럼의 표준편차로 계산
ㄴ 정규화: 최소값, 최대값으로 범위를 최대한으로 맞춰주는 방법
| from sklearn.preprocessing import StandardScaler, MinMaxScaler |
표준화로 피쳐 스케일링: StandardScaler
- 사용 방법:
1. 변수를 만들어준다.
2. 이 변수에게 일을 시킨다.
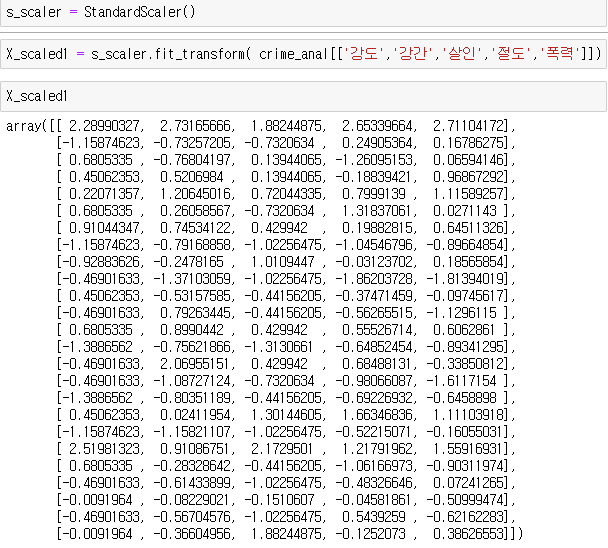
| s_scaler = StandardScaler() X_scaled1 = s_scaler.fit_transform( crime_anal[['강도','강간','살인','절도','폭력']]) |
ㄴ 각 컬럼들만 바꿨음
ㄴ trnasform: 바꿔달라,
ㄴ fit: 알아서 평균과 표준편차를 구해서 바꿔달라
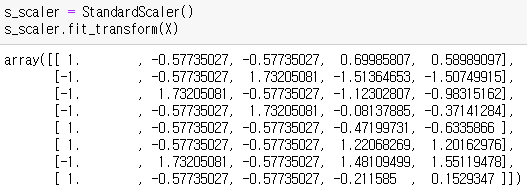
ex) 피쳐 스케일링도, X 따로 ,y 따로 한다
| s_scaler = StandardScaler() s_scaler.fit_transform(X) |
정규화로 피쳐 스케일링: MinMaxScaler
- 사용 방법:
1. 변수를 만들어준다.
2. 이 변수에게 일을 시킨다.
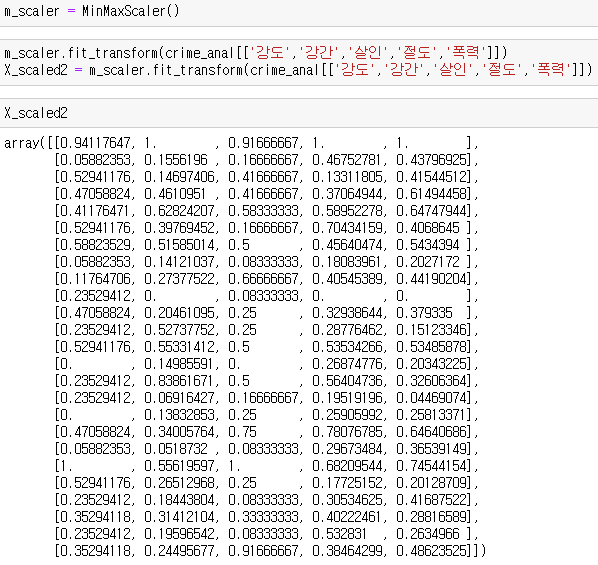
| m_scaler = MinMaxScaler() X_scaled2 = m_scaler.fit_transform( crime_anal[['강도','강간','살인','절도','폭력']]) |
ㄴ 최대값과 최소값을 가져와서 바꿔달라
ㄴ 각 컬럼의 최대값, 최소값으로 계산
ㄴ 결과값은 무조건 0과 1사이의 실수
ㄴ StandardScale은 마이너스도 있다.
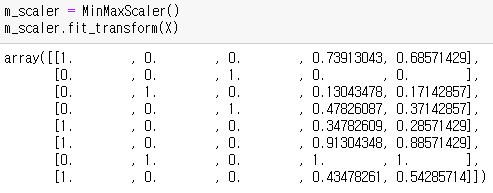
ex)
| m_scaler = MinMaxScaler() m_scaler.fit_transform(X) |
—---
- 한번에 둘 다 사용하면 안된다.
- 둘 중에 하나를 사용하라, 성능은 크게 차이가 없다.
'프로그래밍 언어 > Python' 카테고리의 다른 글
| 파이썬으로 비밀번호 유추하기, 경우의 수 도출 (0) | 2022.06.04 |
|---|---|
| [Python] 넘파이/판다스 타임 시리즈: datetime64, pd.to_datetime(), pd.to_timedelta(), pd.date_range() (0) | 2022.05.06 |
| [Python] 구글맵 API: gmaps.geocode (0) | 2022.05.05 |
| [Python] 피벗 테이블, Pivot Table: pd.pivot_table() (0) | 2022.05.05 |
| [Python] 차트 한글처리 코드 (0) | 2022.05.05 |



