반응형
- 실습: star wars 를 본 사람들에게 영화를 추천할 것입니다. 5개의 추천 영화 제목을 찾으세요.
ㄴ힌트 : 먼저 star wars 의 정확한 이름을 검색해서 찾으세요. 그리고 나서 스타워즈를 본 유저의 데이터를 가져와서, 위와 같이 상관관계분석을 합니다.
| movies_rating_df['title'].unique() # 찾아오는 방법은 또 있다. # moive_titles_df.loc[moive_titles_df['title'].str.lower().str.contains('star'),] # ...에서도 찾을 수 있다. df['Star Wars (1977)'] Startwars_corr = df.corrwith(df['Star Wars (1977)']) # 스타워즈와 모든 컬럼의 관계 Startwars_corr = Startwars_corr.to_frame() Startwars_corr.columns = ['correlation'] Startwars_corr = Startwars_corr.join(ratings_mean_count_df['count']) Startwars_corr.dropna(inplace = True) Startwars_corr.loc[Startwars_corr['count'] > 80, ].sort_values('correlation',ascending = False).head(6) |
- 전체 데이터셋에 대한 Item-Based Collaborative Filter을 만들자!
# 전체 상관계수 # min_perods: 상관계수 구할 때, Non-nan 숫자가 있는 것이 몇개 이상이라는 것 movie_corr = df.corr(min_periods = 80) # 최소 80개 이상 데이터가 있는 것만 상관계수 뽑아라 |

- 나의 별점 정보를 가지고, 영화를 추천해달라고 할 것이다!
ㄴ 내 영화 별점 정보는 My_ratings.csv 파일에 있다.
| myRatings = pd.read_csv('My_ratings.csv') myRatings['Movie Name'][0] movie_name = myRatings['Movie Name'][0] |

movie_corr = df.corr(min_periods = 80)
| # 아까, 타이타닉과/스타워즈의 관계 등이랑 같은 상황임. # 내가 좋아하는 영화와의 상관계수 movie_corr[movie_name] movie_corr[movie_name].dropna() movie_corr[movie_name].dropna().sort_values(ascending = False) recom_movies = movie_corr[movie_name].dropna().sort_values(ascending = False).to_frame() recom_movies.columns = ['correlation'] |


| # 가중치: 내가 준 점수 * 상관계수값 myRatings['Ratings'][0] * recom_movies['correlation'] recom_movies['weight'] = myRatings['Ratings'][0] * recom_movies['correlation'] recom_movies # 101 달마시안에 대한, 상관관계수를 가져온거고, 그에 대한 가중치를 가져온 것. |

- 이제는 나머지 내가 본 영화들도 추천 영화 똑같이 가져오자.
| movie_name2 = myRatings['Movie Name'][1] # 스페이스 오디세이라는 컬럼만 가져오라는 뜻 # 가져와서 dropna()를 하는 것. -> 정렬(ascending = False) -> movie_corr[movie_name2] |
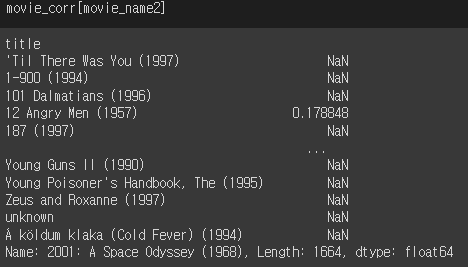
| recom_movie2 = movie_corr[movie_name2].dropna().sort_values(ascending = False).to_frame() recom_movie2.columns = ['correlation'] myRatings['Ratings'][1] * recom_movie2['correlation'] recom_movie2['weight'] = myRatings['Ratings'][1] * recom_movie2['correlation'] |

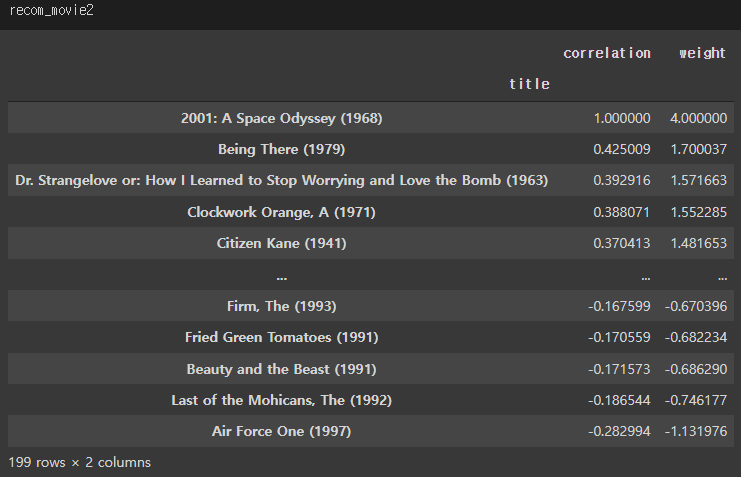
- 위의 추천영화 작업을 자동화 하기위한 파이프라인을 만드시오.
ㄴ 힌트 : 반복문을 사용하여 비슷한영화에 대한 데이터프레임을 만들고, 이를 아래 빈 데이터프레임에 계속하여 추가하시오. 반복문이 끝나면, 아래 데이터프레임을 wegiht 컬럼으로 정렬하면 됩니다.
similar_movies_list = pd.DataFrame() myRatings # 내가 본 영화 데이터 # movie_corr: 영화 상관계수 myRatings.shape # 튜플의 억세스는 리스트와 같다. # myRatings.shape[0] = 3 |

# 아까 했던 코드 순서 # 1. 내가 본 영화의 이름을 가져온다. # 내가 본 영화는 여러개 일 수 있기 때문에, 반복문을 사용한다. # 비어있는 데이터프레임에 myRatings에서 가져온 데이터를 해당 영화 관련해서 하나씩 넣는다. similar_movies_list = pd.DataFrame() for i in range(myRatings.shape[0]): movie_name = myRatings['Movie Name'][i] recom_movies = movie_corr[movie_name].dropna().sort_values(ascending = False).to_frame() # 컬럼이름 바꾸기 recom_movies.columns = ['correlation'] # 가중치가 필요함. 내가 준 함수는 myRatings에 있음, recom_movies['weight'] = myRatings['Ratings'][i] * recom_movies['correlation'] # 위에서 만든 데이터 프레임에다가 추가를 해준다. similar_movies_list = similar_movies_list.append(recom_movies) |
# 1. weight로 정렬한다. 이 이유는? 내가 준 별점이 반영된 컬럼이 weight 컬럼이니까. similar_movies_list.sort_values('weight',ascending = False) similar_movies_list = similar_movies_list.sort_values('weight',ascending = False) |

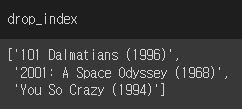
| # 2. 내가 본 영화는, 이 데이터 프레임에서 삭제한다. drop_index = myRatings['Movie Name'].to_list() # 반복문. 인덱스에 있니? 물어보고, 없으면 삭제 for name in drop_index : if name in similar_movies_list.index: similar_movies_list.drop(name,axis=0, inplace = True) # 내가 본 영화는 빠져있다. |
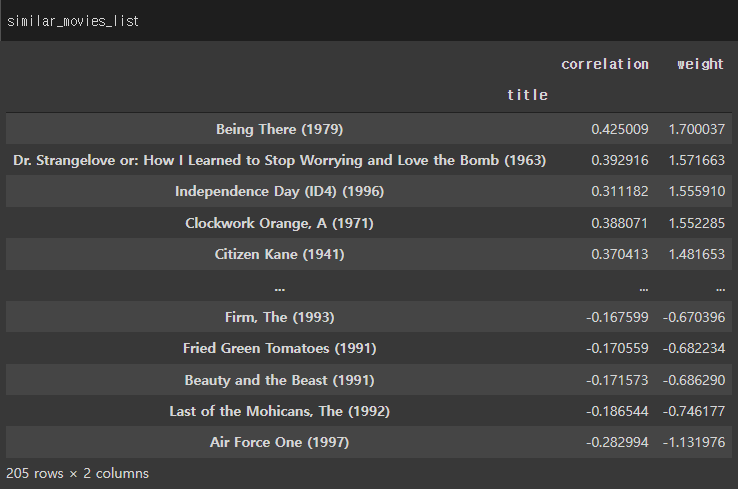
| # 3. 추천 영화가 중복되는 경우도 발생한다. # 따라서, 중복된 영화가 있을 경우는, weight가 가장 높은 값으로만 추천해준다. # 즉, 영화이름별로, weight가 가장 높은 데이터를 가져와서, 웨이트로 정렬해준다. similar_movies_list.reset_index() # 어머 중복데이터가 있네! similar_movies_list.reset_index()['title'].value_counts() similar_movies_list.groupby('title')['weight'].max() similar_movies_list.groupby('title')['weight'].max().sort_values(ascending = False) |

전체적인 흐름:
myRatings = pd.read_csv('My_ratings.csv') movie_name = myRatings['Movie Name'][0] # 내가 좋아하는 영화와의 상관계수 movie_corr[movie_name] movie_corr[movie_name].dropna() movie_corr[movie_name].dropna().sort_values(ascending = False) recom_movies = movie_corr[movie_name].dropna().sort_values(ascending = False).to_frame() recom_movies.columns = ['correlation'] myRatings['Ratings'][0] # 가중치: 내가 준 점수 * 상관계수값 myRatings['Ratings'][0] * recom_movies['correlation'] recom_movies['weight'] = myRatings['Ratings'][0] * recom_movies['correlation'] # 101 달마시안에 대한, 상관관계수를 가져온거고, 그에 대한 가중치를 가져온 것. # 아까 했던 코드 순서 # 1. 내가 본 영화의 이름을 가져온다. # 내가 본 영화는 여러개 일 수 있기 때문에, 반복문을 사용한다. # 비어있는 데이터프레임에 myRatings에서 가져온 데이터를 해당 영화 관련해서 하나씩 넣는다. similar_movies_list = pd.DataFrame() for i in range(myRatings.shape[0]): movie_name = myRatings['Movie Name'][i] recom_movies = movie_corr[movie_name].dropna().sort_values(ascending = False).to_frame() # 컬럼이름 바꾸기 recom_movies.columns = ['correlation'] # 가중치가 필요함. 내가 준 함수는 myRatings에 있음, recom_movies['weight'] = myRatings['Ratings'][i] * recom_movies['correlation'] # 위에서 만든 데이터 프레임에다가 추가를 해준다. similar_movies_list = similar_movies_list.append(recom_movies) # 1. weight로 정렬한다. 이 이유는? 내가 준 별점이 반영된 컬럼이 weight 컬럼이니까. similar_movies_list = similar_movies_list.sort_values('weight',ascending = False) # 2. 내가 본 영화는, 이 데이터 프레임에서 삭제한다. drop_index = myRatings['Movie Name'].to_list() # 반복문. 인덱스에 있니? 물어보고, 없으면 삭제 for name in drop_index : if name in similar_movies_list.index: similar_movies_list.drop(name,axis=0, inplace = True) # 내가 본 영화는 빠져있다. similar_movies_list similar_movies_list.reset_index() similar_movies_list.reset_index()['title'].value_counts() similar_movies_list.groupby('title')['weight'].max() similar_movies_list.groupby('title')['weight'].max().sort_values(ascending = False) |
반응형
'Python-머신러닝' 카테고리의 다른 글
| 영화 추천 시스템 1/2 (0) | 2022.05.15 |
|---|---|
| 범죄율 예측: pd.to_datetime(), dt.weekday, (0) | 2022.05.15 |
| 가격 예측 알고리즘: Facebook Prophet (0) | 2022.05.15 |
| 댓글의 긍정/부정 인공지능 알고리즘(나이브 베이즈/서포터 백터 머신) (0) | 2022.05.15 |
| 나이브 베이즈(Naive Bayes) 및 구글 코랩( Colab), Word Cloud2 (0) | 2022.05.15 |



