추천시스템:
어떤 사람이 한 영화를 봤다.
User-Based Collaborative Filtering
- 유저 기반으로, 유저가 사거나 본 아이템을 행렬로 만든다
- 유저간의 유사도를 측정하여, 비슷한 유저를 찾는다.
- 비슷한 유저를 기반으로 아이템을 추천해준다.
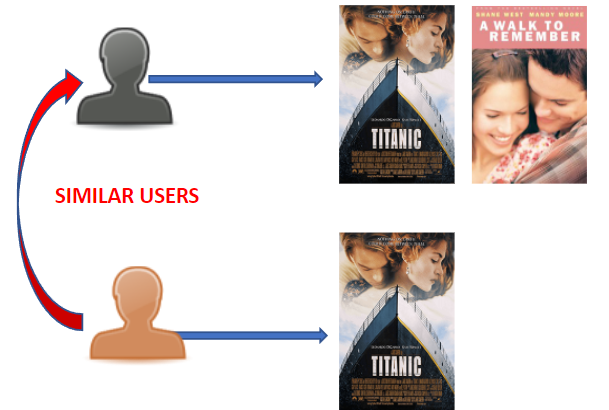
-> 상당히 기본적인 방법이나 한계가 있더라.
- 아이템(제품/영화 등)보다 유저가 많아지면, 복잡도가 올라간다.
- 유저의 기호는 변한다. (오늘은 액션 시청, 내일은 로맨스 시청)
- 따라서 유저기반의 협업 필터링보다, 아이템 기반의 협업 필터링을 사용한다.
Item-Based Collaborative Filtering
- 사람이 아닌 아이템(제품/영화 등)간의 관계를 기반으로 추천해주는 시스템
- 두 사람이, 타이타닉도 봤고, 웤투리멤버도 시청했다.
ㄴ 이러면 타이타닉과 워크리멤버는 상관관계가 있는 것.
ㄴ 따라서 새로운 유저가 타이타닉은 시청하였으나, 웤투리멤버를 아직 시청 안했다면, 이 사람에게 웤투리멤버를 추천해준다.

-> 아이템(제품/영화 등)간이 비슷한지 유사도를 측정하라.
ㄴ 비슷하다는 것은 관계.
ㄴ 관계 = 상관계수
ㄴ 상관계수가 비례하면, 관계가 있는 것. 반비례면 반대이고, 0이면 관계가 없는 것.
영화 추천 시스템
- 추천시스템은 영화나 노래등을 추천하는데 사용되며, 주로 관심사나 이용 내역을 기반으로 추천한다.
- 이 노트북에서는, Item-based Collaborative Filtering 으로 추천시스템을 구현한다.
- Dataset MovieLens: https://grouplens.org/datasets/movielens/100k/
- 작업환경: Colab
| import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline from google.colab import drive drive.mount('/content/drive') import os os.chdir('/content/drive/MyDrive/Colab Notebooks') movie_titles_df = pd.read_csv('Movie_Id_Titles.csv') movies_rating_df = pd.read_csv('u.data',sep = '\t', names = ['user_id','item_id','rating','timestamp']) |


- movies_rating_df에서 timestamp 컬럼 제거
- 두 개의 데이터 프레임 합치기
| movies_rating_df.drop('timestamp',axis=1, inplace = True) movies_rating_df = pd.merge(movies_rating_df,movie_titles_df, on = 'item_id') |

- 각 영화 제목별로, 별점에 대한 기본 통계치(최대, 최소, 중앙, 표준편차, ¼, ¾ 값)을 보여주세요.
| movies_rating_df.groupby('title')['rating'].describe() |

- 각 영화별 별점의 평균과 몇개의 데이터가 있는지 구하고 각각의 변수에 저장하시오.
- 두 데이터 프레임을 합치시오
| ratings_df_mean = movies_rating_df.groupby('title')['rating'].mean() ratings_df_count = movies_rating_df['title'].value_counts() # size()도 됨. # 데이터 시리즈를 데이터 프레임으로 바꾸는 방법 ratings_df_mean.to_frame() ratings_df_mean1 = ratings_df_mean.to_frame() ratings_df_mean1.columns = ['mean'] # ㄴ 데이터 프레임 컬럼 이름 바꿔줌 ratings_df_count1 = ratings_df_count.to_frame() ratings_df_count1.columns = ['count'] ratings_df_mean1.join(ratings_df_count1) ratings_mean_count_df = ratings_df_mean1.join(ratings_df_count1) # pandas의 join 함수는, 데이터 프레임끼리 합치는 함수이되, 인덱스가 같은것들끼리 알아서 합쳐준다. # 시리즈는 join함수가 없다. # 데이터 프레임의 join(), 인덱스가 동일할 때, 옆으로 붙여주는 함수 # join()안에다가 데이터프레임을 넣어준다. |


ratings_mean_count_df

- count가 가장 많은 것부터 정렬하여 100개까지만 보여주세요.
ratings_mean_count_df.sort_values('count', ascending= False).head(100) |

movies_rating_df.groupby('user_id')['user_id'].count() # movies_rating_df['user_id].value_counts() 와 같은 뜻임 |

- 영화 하나에 대한, Item-Based Collaborative Filtering 수행!
ㄴ title이 가로(컬럼)이 되어야하고, 세로(인덱스)는 사람(user_id)가 되어야한다.
ㄴ movies_rating_df 를 가지고 아래 피봇테이블 합니다.
ㄴ 상관관계를 구하고 싶으면, 내가 비교하고,알고싶은 데이터가 컬럼에 있어야한다.
movies_rating_df

- 피봇 테이블을 이용하여, 콜라보레이티브 필터링 포맷으로 변경.
df = movies_rating_df.pivot_table(values = 'rating', index = 'user_id', columns = 'title', aggfunc = "mean") |

| df['Titanic (1997)'] |

| # corrwith() 괄호 안에있는 데이터와 전체의 특정 관계를 나타낸다. # corr은 코릴레이션의 약자. 상관분석이라는 뜻 df.corrwith(df['Titanic (1997)']) #전체와 타이타닉의 상관계수를 보는 것 # 밑에 영문명은 0으로 되어있는 경우도 있는데, 난 그래도 무시하고 할께 라는 뜻. |

| titanic_corr = df.corrwith(df['Titanic (1997)']) titanic_corr = titanic_corr.to_frame() titanic_corr.columns = ['correlation'] |

| titanic_corr = titanic_corr.join(ratings_mean_count_df['count']) |

| titanic_corr.dropna(inplace = True) titanic_corr.sort_values('correlation',ascending= False) titanic_corr.loc [ titanic_corr['count'] > 80, ].sort_values('correlation',ascending = False) |
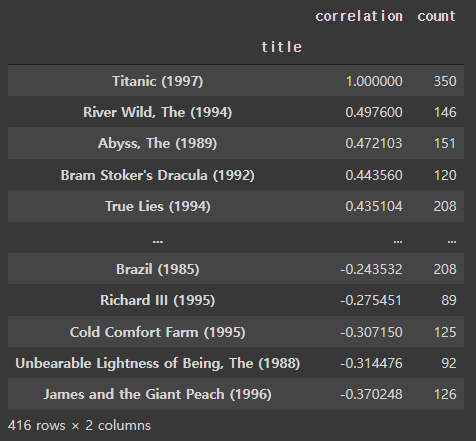
전체 흐름:
movie_titles_df = pd.read_csv('Movie_Id_Titles.csv') movies_rating_df = pd.read_csv('u.data',sep = '\t', names = ['user_id','item_id','rating','timestamp']) movies_rating_df.drop('timestamp',axis=1, inplace = True) movies_rating_df = pd.merge(movies_rating_df,movie_titles_df, on = 'item_id') df = movies_rating_df.pivot_table(values = 'rating', index = 'user_id', columns = 'title', aggfunc = "mean") titanic_corr = df.corrwith(df['Titanic (1997)']) titanic_corr = titanic_corr.to_frame() titanic_corr.columns = ['correlation'] titanic_corr = titanic_corr.join(ratings_mean_count_df['count']) titanic_corr.dropna(inplace = True) titanic_corr.loc [ titanic_corr['count'] > 80, ].sort_values('correlation',ascending = False) |
'Python-머신러닝' 카테고리의 다른 글
| 영화 추천 시스템 2/2 (0) | 2022.05.15 |
|---|---|
| 범죄율 예측: pd.to_datetime(), dt.weekday, (0) | 2022.05.15 |
| 가격 예측 알고리즘: Facebook Prophet (0) | 2022.05.15 |
| 댓글의 긍정/부정 인공지능 알고리즘(나이브 베이즈/서포터 백터 머신) (0) | 2022.05.15 |
| 나이브 베이즈(Naive Bayes) 및 구글 코랩( Colab), Word Cloud2 (0) | 2022.05.15 |



