데이터 정렬
- Sorting and Ordering
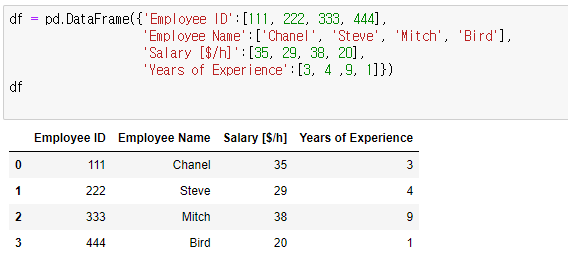
- 판다스 데이터프레임 변수명[컬럼명]. sort_values(컬럼명)
ㄴ 기본적으로 오름차순으로 설정이 되어있다.
ㄴ ex) 경력을 오름차순으로 정렬
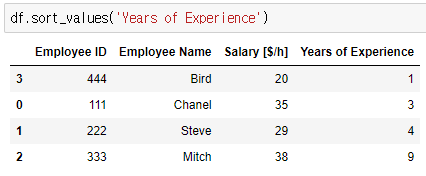
- 내림차순: ascending=False
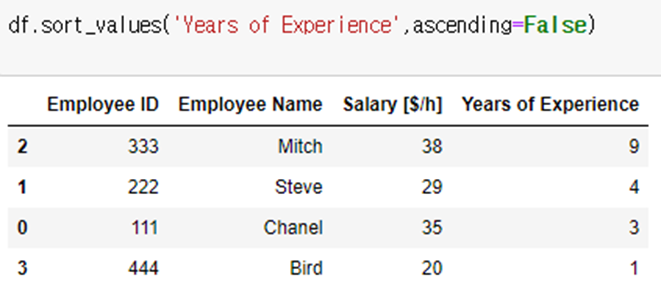
Ex) 이름으로 먼저 정리하고, 이름이 같을 경우에는, 경력으로 정렬
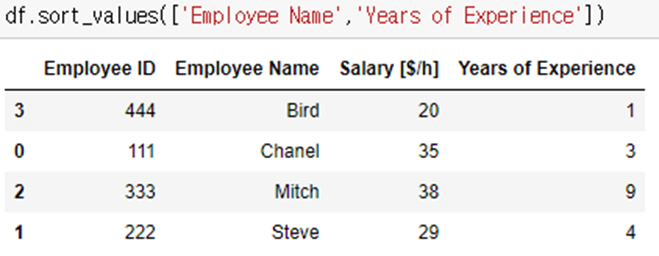
Ex) 이름과 경력으로 정렬하되, 이름은 내림차순, 경력은 오름차순으로 정렬!
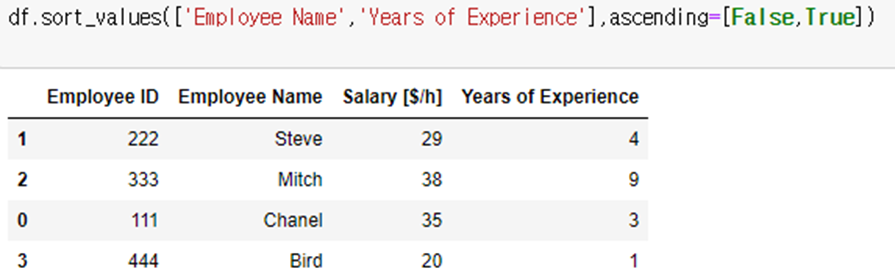
csv로 저장/불러오기/처리
- csv : comma separated values => 데이터는 콤마로 구분합니다.
- csv의 규칙! 맨 위의 행은, 컬럼명을 적어줍니다.
- 불러오기: df = pd.read_csv('my_test.csv')
ㄴ unnamed 없애는 방법:
| 방법1 (불러오고나서): df.drop('Unnamed: 0',axis =1) 방법2 (슬라이싱): df.loc[:,"country": ] 방법3: df = pd.read_csv('data/winemag-data_first150k.csv', index_col= 'Unnamed: 0') ㄴ col = column 방법4: (방법3과 비슷하다) pd.read_csv('data/winemag-data_first150k.csv', index_col= 0) |
ex)
df = pd.read_csv(DataUrl, encoding='euc-kr')
ㄴ encoding 를 따로 지정할 수도 있음.
ex)
df = pd.read_csv('data/age.csv',encoding = 'cp949',thousands= ',')
ㄴ 숫자 사이에 ,(콤마) 있는 걸 문자열이 아니라 숫자로 처리하겠다는 뜻
ㄴ 천 단위에 콤마 있다라는 뜻: thousands= ','
ex)
pop_Seoul = pd.read_excel('data/population_in_Seoul.xls',
header=2,
usecols='B, D, G, J, N')
ㄴ header = 0,1,2 헤더를 3개로 사용하겠다.
ㄴ usecol = 엑셀 파일의 보여지는 셀 컬럼을 이용하겠다는 뜻
- 저장: df.to_csv('my_test2.csv')
ㄴ 저장경로는 지금 작업하고 있는 파일과 같은 폴더에 위치한다.



