웹 대시보드로 만드는 이유는 유저와의 상호소통을 위해서.
Streamlit 에서 예측 인공지능 실행
- colab/ Jupyter Notebook
- 전에 만들어놨던 car_purchasing_data파일에서 인공지능 학습을 완료한 스케일러와 리그레서를 저장하여 가져온다.
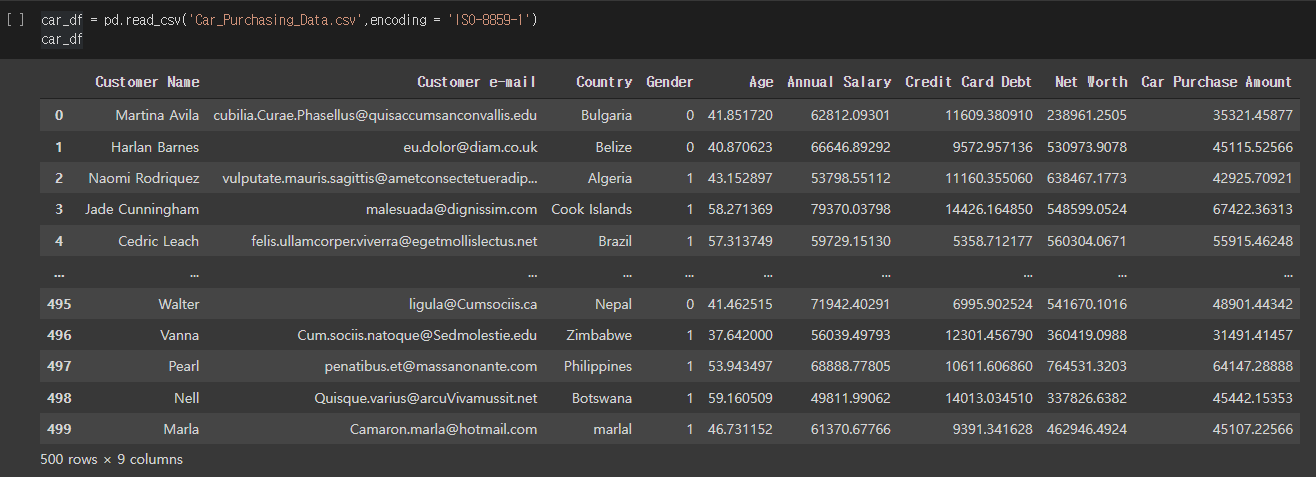
| import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns from google.colab import drive drive.mount('/content/drive') import os os.chdir('/content/drive/MyDrive/Colab Notebooks') # change directory car_df = pd.read_csv('Car_Purchasing_Data.csv',encoding = 'ISO-8859-1') |
X,y설정
| X = car_df.loc[:, 'Gender': 'Net Worth'] y = car_df['Car Purchase Amount'] |
X 스케일러 적용
| from sklearn.preprocessing import MinMaxScaler scaler_X = MinMaxScaler() X= scaler_X.fit_transform(X) |
y 스케일러 적용
# 스케일러는 무조건 2차원으로 들어가야한다. 현재 y는 1차원
# 시리즈는 reshape이 없다.
| y = y.values.reshape(500,1) scaler_y = MinMaxScaler() y = scaler_y.fit_transform(y) |
리니어 리그레션으로 모델링 및 학습
| from sklearn.model_selection import train_test_split X_train,X_test, y_train, y_test = train_test_split(X,y, test_size=0.25, random_state= 50) |
| from sklearn.linear_model import LinearRegression regressor = LinearRegression() regressor.fit(X_train, y_train) |
| y_pred = regressor.predict(X_test) error = y_test - y_pred (error**2).mean() |
인공지능과, X용 스케일러, y용 스케일러를 파일로 저장한다.
| import joblib joblib.dump(regressor,'regressor.pkl') |
# 파일명은 변수명과 똑같이 저장
# 확장자명 피클 pkl
| joblib.dump(scaler_X, 'scaler_X.pkl') joblib.dump(scaler_y, 'scaler_y.pkl') |
- 유저에게 고객 이름 컬럼을 검색할수 있는 기능
# 1. 유저한테 검색어를 입력받는다.
# 2. 검색어를 고객이름 컬럼에 들어있는 데이터 가져온다.
# 3. 화면에 보여준다.
| car_df.loc[car_df['Customer Name'].str.lower().str.contains('he'), ] |
–
- Git 허브에서 새로운 레파지토리 생성 후에, vscode에 진입
ㄴ 각 app.py, app_home.py, app_eda.py, app_ml.py 파일을 생성해준다.
ㄴ app.py가 메인 파일. 다른 각 파일에서는 함수 생성할 것.
(이하 app.py)
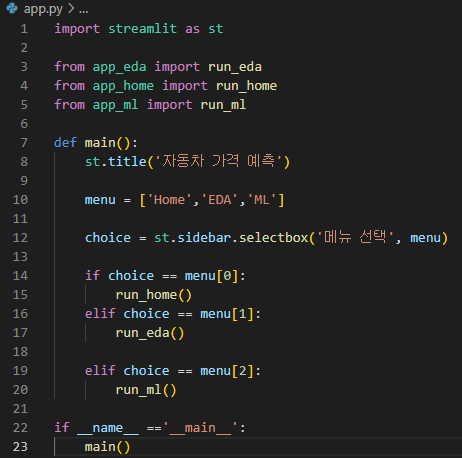
| import streamlit as st from app_eda import run_eda from app_home import run_home from app_ml import run_ml def main(): st.title('자동차 가격 예측') menu = ['Home','EDA','ML'] choice = st.sidebar.selectbox('메뉴 선택', menu) if choice == menu[0]: run_home() elif choice == menu[1]: run_eda() elif choice == menu[2]: run_ml() if __name__ =='__main__': main() |
(이하 app_home.py)

| import streamlit as st def run_home(): st.subheader('이 앱은 고객 데이터와 자동차 구매데이터에 대한 내용입니다.') st.text('왼쪽 사이드바에서 원하는 항목을 선택하세요.') |
(이하 app_eda.py)
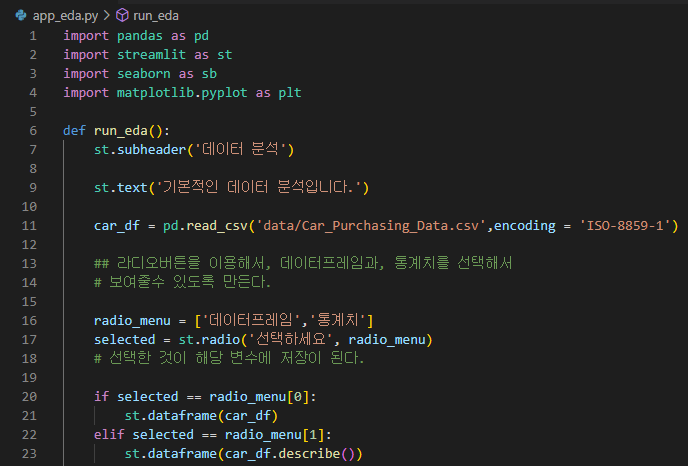
| import pandas as pd import streamlit as st import seaborn as sb import matplotlib.pyplot as plt def run_eda(): st.subheader('데이터 분석') st.text('기본적인 데이터 분석입니다.') car_df = pd.read_csv('data/Car_Purchasing_Data.csv',encoding = 'ISO-8859-1') |
- 라디오버튼을 이용해서, 데이터프레임과, 통계치를 선택해서 보여줄수 있도록 만든다.
| radio_menu = ['데이터프레임','통계치'] selected = st.radio('선택하세요', radio_menu) # 선택한 것이 해당 변수에 저장이 된다. if selected == radio_menu[0]: st.dataframe(car_df) elif selected == radio_menu[1]: st.dataframe(car_df.describe()) |

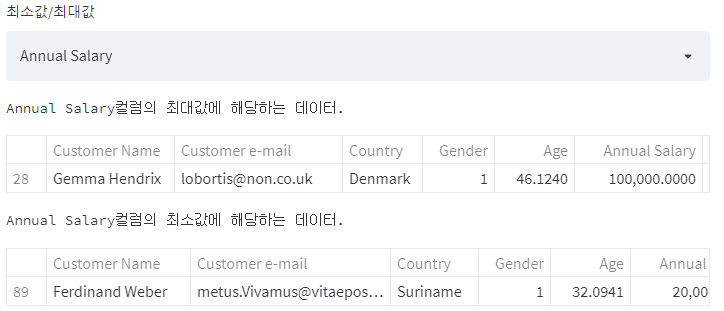
- 컬럼명을 보여주고, 컬럼을 선택하면, 해당 컬럼의 최대값 데이터와, 최소값 데이터를 보여준다.
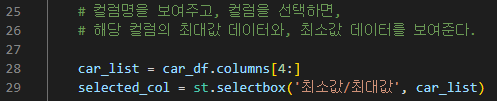
| car_list = car_df.columns[4:] selected_col = st.selectbox('최소값/최대값', car_list) |
- 연봉 제일 높은 사람
# car_df.loc[car_df['Annual Salary'] == car_df['Annual Salary'].max(),]
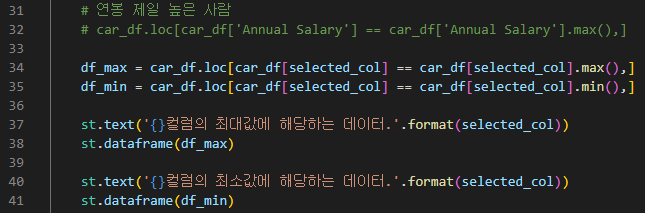
| df_max = car_df.loc[car_df[selected_col] == car_df[selected_col].max(),] df_min = car_df.loc[car_df[selected_col] == car_df[selected_col].min(),] st.text('{}컬럼의 최대값에 해당하는 데이터.'.format(selected_col)) st.dataframe(df_max) st.text('{}컬럼의 최소값에 해당하는 데이터.'.format(selected_col)) st.dataframe(df_min) |
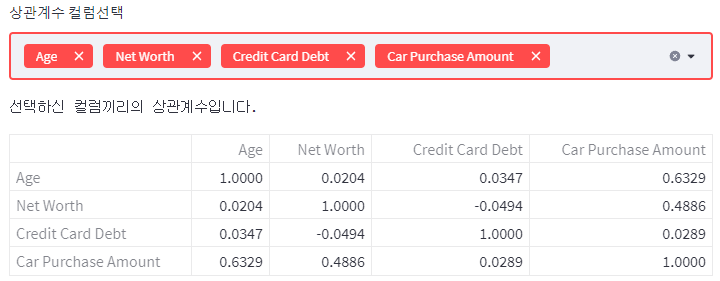
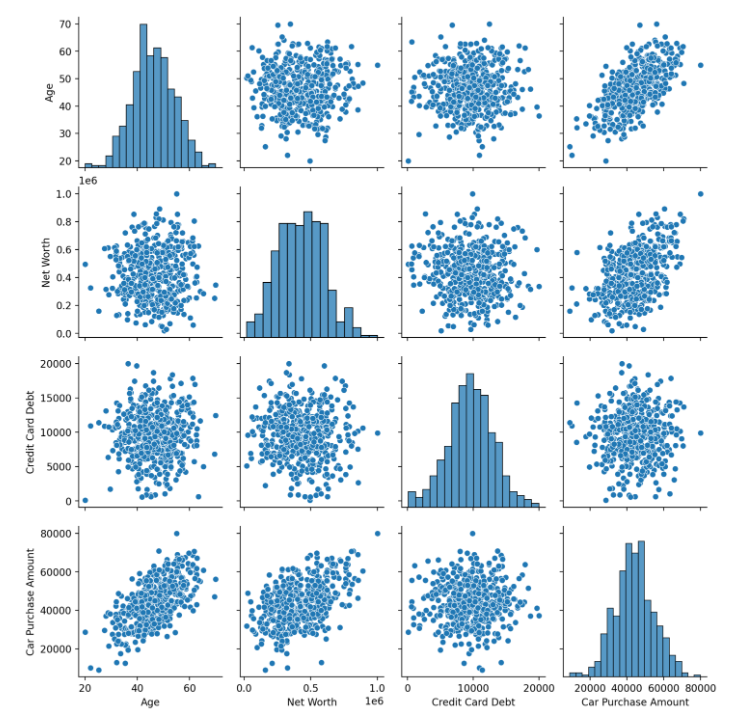
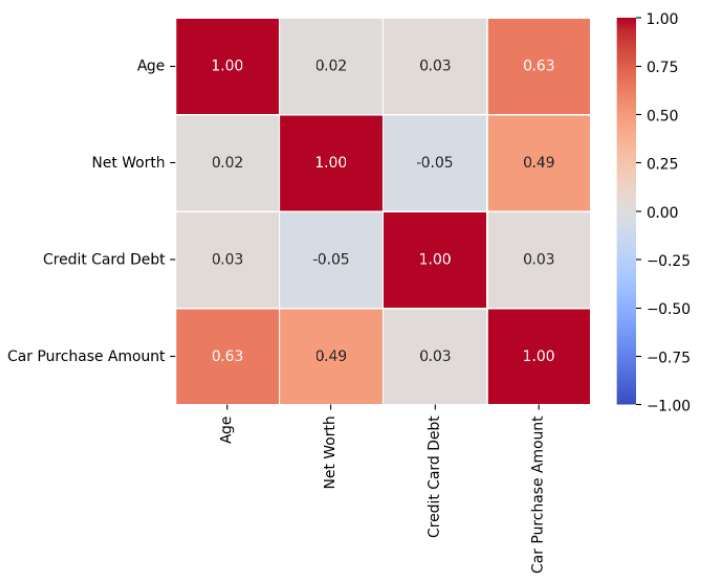
# 유저가 선택한 컬럼들만, pairplot 그리고 그 아래, 상관계수를 보여준다.
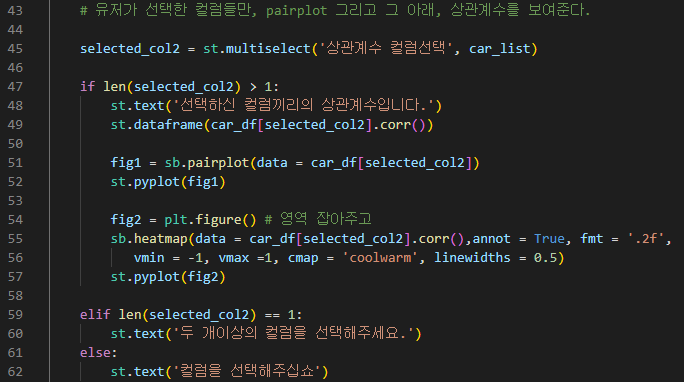
| selected_col2 = st.multiselect('상관계수 컬럼선택', car_list) if len(selected_col2) > 1: st.text('선택하신 컬럼끼리의 상관계수입니다.') st.dataframe(car_df[selected_col2].corr()) fig1 = sb.pairplot(data = car_df[selected_col2]) st.pyplot(fig1) fig2 = plt.figure() # 영역 잡아주고 sb.heatmap(data = car_df[selected_col2].corr(),annot = True, fmt = '.2f', vmin = -1, vmax =1, cmap = 'coolwarm', linewidths = 0.5) st.pyplot(fig2) elif len(selected_col2) == 1: st.text('두 개이상의 컬럼을 선택해주세요.') else: st.text('컬럼을 선택해주십쇼') |

fig2 = plt.figure() ~ st.pyplot(fig2)
matplot하고 searborn만 요런 문법 형식으로만 스트림릿에 반영된다.
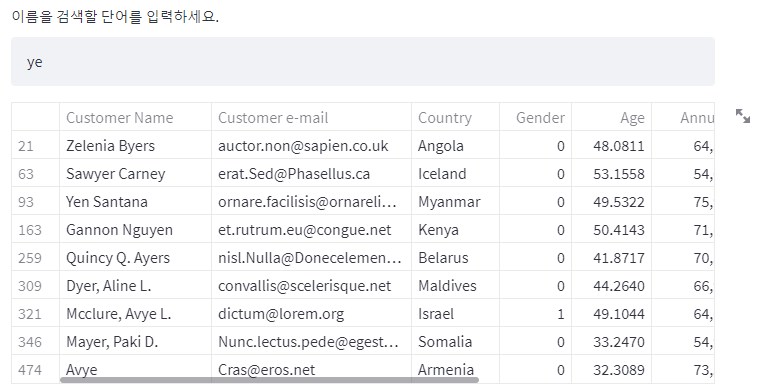
고객 이름 컬럼을 검색할 수 있도록 만듭니다.
- he라고 넣으면, he가 이름에 들어가있는 고개들의 데이터를 가져옵니다.
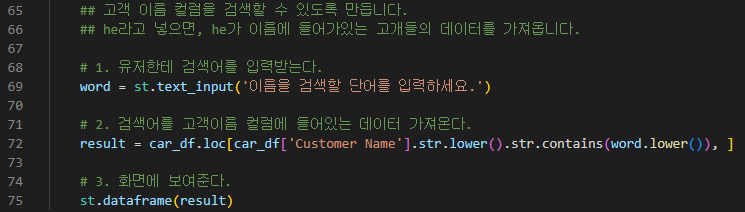
| # 1. 유저한테 검색어를 입력받는다. word = st.text_input('이름을 검색할 단어를 입력하세요.') # 2. 검색어를 고객이름 컬럼에 들어있는 데이터 가져온다. result = car_df.loc[car_df['Customer Name'].str.lower().str.contains(word.lower()), ] # 3. 화면에 보여준다. st.dataframe(result) |
(이하 app_ml.py)
- 주피터 노트북/ Colab에서 저장한 regressor, scaler_X, scaler_y를 현재 app.py가 있는 깃허브 ‘data’ 폴더 안에다가 이동해둔다.
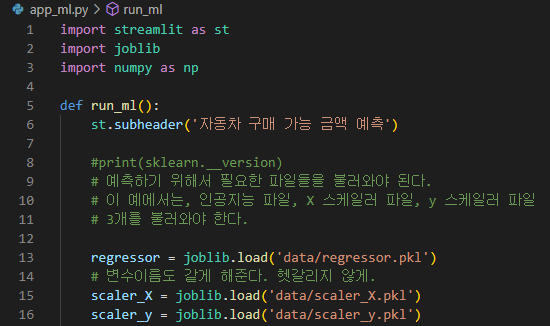
| import streamlit as st import joblib import numpy as np def run_ml(): st.subheader('자동차 구매 가능 금액 예측') regressor = joblib.load('data/regressor.pkl') scaler_X = joblib.load('data/scaler_X.pkl') scaler_y = joblib.load('data/scaler_y.pkl') |
# print(sklearn.__version)
# 예측하기 위해서 필요한 파일들을 불러와야 된다.
# 이 예에서는, 인공지능 파일, X 스케일러 파일, y 스케일러 파일
# 3개를 불러와야 한다.
# 변수이름도 같게 해준다. 헷갈리지 않게.
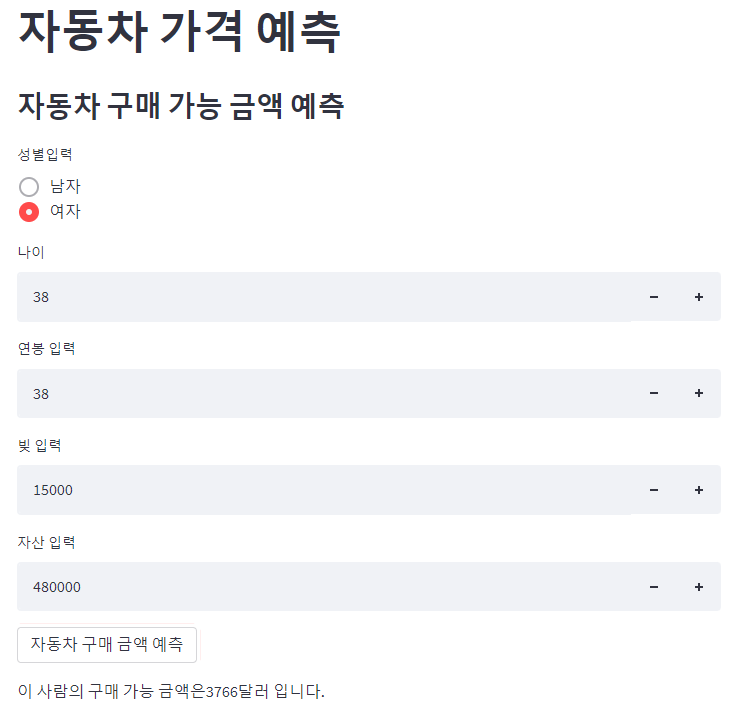
- 유저가 앱을 통해서 데이터를 입력했습니다. 이 사람은 얼마정도의 차를 구매할 수 있을지 예측해서, 그 사람에게 맞는 차를 보여주려 합니다.
ㄴ 여자이고, 나이는 38살, 연봉은 78,000달러, 카드 빚은 15,000달러이고, 자산은 480,000달러입니다.
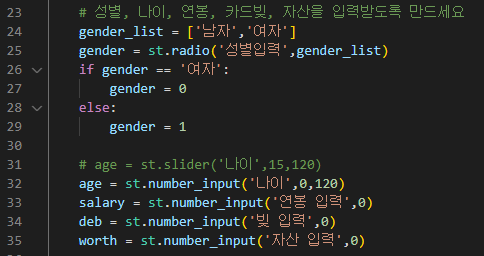
# 성별, 나이, 연봉, 카드빚, 자산을 입력받도록 만드세요
| gender_list = ['남자','여자'] gender = st.radio('성별입력',gender_list) if gender == '여자': gender = 0 else: gender = 1 # age = st.slider('나이',15,120) age = st.number_input('나이',0,120) salary = st.number_input('연봉 입력',0) deb = st.number_input('빚 입력',0) worth = st.number_input('자산 입력',0) |
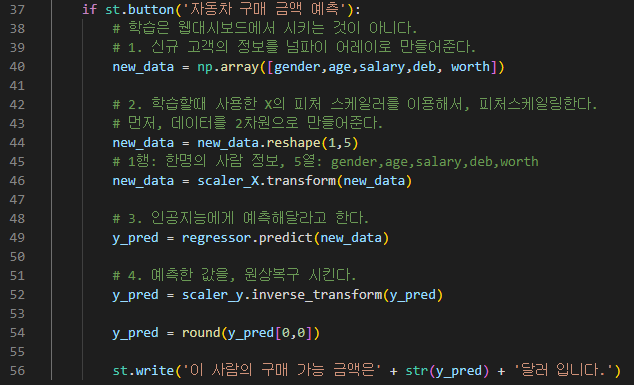
# 학습은 웹대시보드에서 시키는 것이 아니다.
ㄴ 주피터 노트북에서 확인한것만 vscode로 옮겨온다.
# 1. 신규 고객의 정보를 넘파이 어레이로 만들어준다.
# 2. 학습할때 사용한 X의 피처 스케일러를 이용해서, 피처스케일링한다.
ㄴ 먼저, 데이터를 2차원으로 만들어준다.
# 3. 인공지능에게 예측해달라고 한다.
# 4. 예측한 값을, 원상복구 시킨다.
| if st.button('자동차 구매 금액 예측'): new_data = np.array([gender,age,salary,deb, worth]) new_data = new_data.reshape(1,5) # 1행: 한명의 사람 정보, 5열: gender,age,salary,deb,worth new_data = scaler_X.transform(new_data) y_pred = regressor.predict(new_data) y_pred = scaler_y.inverse_transform(y_pred) y_pred = round(y_pred[0,0]) st.write('이 사람의 구매 가능 금액은' + str(y_pred) + '달러 입니다.') |
'Github & Streamlit' 카테고리의 다른 글
| 리뷰 긍정/부정 앱 만들기: 긍정/부정 판단하는 인공지능 삽입 (0) | 2022.06.04 |
|---|---|
| streamlit이 제공하는 차트: Altair 차트, map 차트, plotly pie,bar차트 (0) | 2022.06.01 |
| streamlit 이 제공하는 차트: st.line_chart(), st.area_chart(), st.bar_chart() (0) | 2022.06.01 |
| Streamlit 차트 그리기: fig = plt.figure() , st.pyplot(fig) (0) | 2022.06.01 |
| Streamlit 문법: 파일을 분리해서 만드는 앱 (0) | 2022.06.01 |



