반응형
카테고리컬 데이터 (Categorical Data)
- 반복해서 묶음으로 처리할 수 있는 데이터
- 이메일은 카테고리컬 데이터가 아니다.
- 똑같이 만들수 없는 것을 ‘유니크하다’라고 한다.
- 카테고리컬 데이터가 정해져 있음

- 고유한 값이 몇개인지 계산: 판다스 데이터프레임 변수명[컬럼명].nunique()
ㄴ n은 넘버라는 뜻

- 고유한 값이 무엇인지 추출: 판다스 데이터프레임 변수명[컬럼명].unique()
ㄴ 고유한 값을 내놓는다.
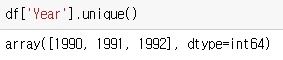
*주의할 점: nan 도 값에 포함한다.

-> nunique()에서도 nan값을 포함한 수치로 계산된다.
카테고리컬 데이터의, 각 데이터별로 묶어서 처리하는 방법
ㄴ '~별로'하면 groupby()함수를 이용하라
ㄴ ‘~에 따른’ 도 groupby() 함수
판다스 데이터프레임 변수명(‘~별로/~에 따른’의 컬럼명)[‘무엇을 계산’하는 컬럼명]
ㄴ ex) 각 년도별로 연봉 총합 구하라.

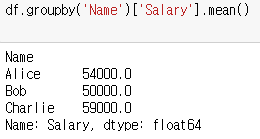
ㄴ ex) 각 직원별로, 연봉을 평균 얼마씩 받았는지 구하세요.
df.groupby('Name')['Salary'].mean()
ㄴ ex) 년도별, 부서별로 연봉은 총 얼마씩 지급하였는지 구하세요.

집계:
판다스 데이터프레임 변수명(‘~별로/~에 따른’의 컬럼명)[‘무엇을 계산’하는 컬럼명]. Agg()
ㄴ 집계하라는 어그리게이션 함수
ㄴ ex) 년도별 연봉 총합과 평균을 구하세요.

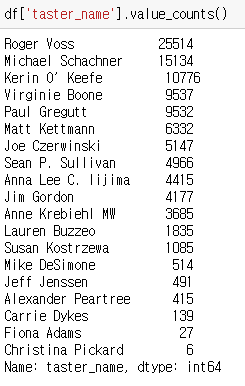
데이터 개수 세기: count(), value_counts()
ㄴ ex) # 컬럼의 데이터별로, 몇 개씩 있는거냐?

- value_counts() : 큰 수치부터 작은 수치까지 자동으로 정렬해준다.
반응형



